Upstage AI Lab 3기 - Data Centric AI
▣ 목차 ▣
1. Data-Centric AI란?
(1-1) Data-Centric AI란
(1-2) Data-Centric AI의 미래
2. 데이터 기획
(2-1) 데이터 구축 프로세스 소개
(2-2) 데이터 구축 기획서 작성
3. 데이터 수집
(3-1) 직접수집
(3-2) 크롤링
(3-3) 오픈소스
(3-4) 크라우드 소싱
(3-5) 데이터 수집시 주의 사항 - 라이선스, 개인정보보호, 윤리
(3-6) 데이터 전처리
4. 데이터 라벨링
(4-1) 라벨링 가이드라인 작성 방법
(4-2) 데이터 라벨링 규칙 설정 1 _ CV
(4-3) 데이터 라벨링 규칙 설정 2 _ NLP
(4-4) 라벨링 툴 소개
5. 데이터 클렌징
(5-1) 데이터 클렌징
(5-2) 데이터 평가 방법 _ IAA
(5-3) IAA를 활용한 데이터 클렌징 방법
6. 데이터 마무리
(6-1) 데이터 스플릿
(6-2) 합성 데이터 _ CV
(6-4) 합성 데이터 _ NLP
(6-6) 액티브 러닝 (이론)
(6-8) 데이터 릴리즈
7. 데이터 제작 실습
(7-1) CV 데이터 제작
(7-2) NLP 데이터 제작
1. Data-Centric AI란?
(1-1) Data-Centric AI란
AI System = Code + Data

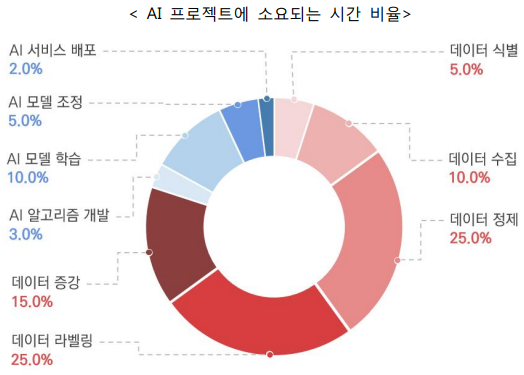

(1-2) Data-Centric AI의 미래


Multilingual LLM

Multilingual Data
- MLQA MultiLingual Question Answering
- Multilingual LibriSpeech
- GEM Benchmark
- BLOOM @ BigScience
- PaLM 2 @ Google
- MMS (Massively Multilingual Speech) @ Meta
Multimodal LLM

Multimodal Data
- VQA Visual Question Answering v2.0
- VidLN Video Localized Narratives
- VDialogUE
- GPT-4 @ OpenAI
- PaLM-E @ Google
- KOSMOS-2 @ Microsoft
Synthetic Data
실제 세상으로부터 수집된 것이 아닌 알고리즘이나 시뮬레이션을 통해 생성된 인위적인 데이터

GPT-4의 결과를 보면, 다양한 분야의 작업을 사람만큼이나 혹은 사람보다도 더 잘 수행할 수 있다는 것을 확인할 수 있음
이는 곧 모델이 생성하는 데이터를 가지고 새로운 모델을 다시 학습할 수 있는 시대가 왔다는 것으로 볼 수 있음

2. 데이터 기획
(2-1) 데이터 구축 프로세스 소개

(2-2) 데이터 구축 기획서 작성

AI Hub 데이터 구축 기획서
1. 구축계획 수립
1.1 구축 목적, 방법, 규모
1.2 데이터 명세서
2. 데이터 구축
2.1 개요
2.2 데이터 수집
2.3 데이터 정제
2.4 데이터 가공
2.5 학습모델 적용방안
3. 데이터 수집
(3-1) 직접수집
이미지/영상 데이터 : 스마트폰, 카메라 등을 통해 찍은 사진, 스캐너를 통해 스캔된 문서 등
텍스트/음성 데이터 : 워드 등을 통해 작성된 문서 파일, 녹음기를 통해 녹음한 음성 파일 등
센서 데이터 : 스마트 워치를 통해 수집된 가속도 센서, GPS 등
(3-2) 크롤링
인터넷에서 정보를 수집하기 위해 자동화된 방식으로 웹페이지를 탐색하는 과정
크롤링의 프로세스
1. 웹사이트 구조 파악 : 크롤링할 웹사이트의 계층 구조, URL 패턴, 페이지 간의 관계 등을 파악
2. 크롤링 도구 선택 : BeautifulSoup, Scrapy, Selenium 등의 파이썬 라이브러리 중 어떤 것을 사용할 것인지 결정
3. URL 수집 : 크롤링할 웹사이트의 주요 페이지 URL을 수집하여 크롤링할 URL 목록을 구성
4. HTTP 요청 및 다운로드 : 선택한 크롤링 도구로 대상 URL에 HTTP GET 요청을 보내고 HTML 소스코드를 다운로드
5. 데이터 추출 : HTML 소스코드를 분석하여 필요한 데이터를 추출
○ 이때, CSS 선택자나 XPath를 사용하여 원하는 HTML 요소를 추출함
6. 데이터 가공 : 추출한 데이터를 원하는 형태에 맞게 가공함
7. 데이터 저장 : 가공된 데이터를 크롤링한 데이터를 로컬 파일 또는 데이터베이스에 저장
8. 4 ~ 7번 과정을 반복
크롤링 라이브러리 간 특징 비교

(3-3) 오픈소스(Open Source)
오픈 소스 소프트웨어 : 누구나 특별한 제한 없이 코드를 보고 사용할 수 있는 오픈 소스 라이선스를 만족하는 소프트웨어
오픈 소스 데이터 : 오픈 소스 소프트웨어처럼, 누구나 특별한 제한 없이 접근 및 이용이 가능한 데이터/데이터셋
대표적인 플랫폼
- 공공데이터포털
- 서울 열린데이터광장
- AI 허브 (AI Hub)
- https://data.mfds.go.kr/cntnts/10
- Kaggle
- PapersWithCode
- UCI ML Repo
- 국가별 공공데이터 포털
(3-4) 크라우드 소싱(Crowdsourcing)
기업 활동의 일부 과정에서 일반 대중을 참여시키는 것
인공지능 데이터를 구축하는 과정에서 데이터를 수집하거나 라벨링할 때 일반 대중을 작업자로 활용

(3-5) 데이터 수집시 주의 사항 - 라이선스, 개인정보보호, 윤리
저작권과 CCL
저작권 (Copyright) : 시, 소설, 음악, 미술, 영화, 연극, 컴퓨터프로그램 등과 같은 '저작물'에 대하여 창작자가 가지는 여러 가지 권리의 전체
크리에이티브 커먼즈 라이선스 (Creative Commons License, CCL; 자유이용허락표시)
: 비영리기구인 크리에이티브 커먼즈에서 만든 저작물 관련 라이선스

개인정보
1) 살아 있는 2) 개인에 관한 3) 정보로서 4) 개인을 알아볼 수 있는 정보
해당 정보만으로는 특정 개인을 알아볼 수 없더라도 5) 다른 정보와 쉽게 결합하여 알아볼 수 있는 정보
1) 사망한 자, 법인, 단체 또는 사물 등에 관한 정보는 개인정보가 아님
2) 여럿이 모여서 이룬 집단의 통계값 등은 개인정보가 아님
3) 정보의 종류, 형태, 성격 등에 관련 없이 모두 개인정보가 될 수 있음
4) 특정 개인을 알아보기 어려운 정보는 개인정보가 아님
○ 이 때, ‘알아보기 어려운’의 주체는 해당 정보를 처리하는 모든 사람에 해당함
5) 결합 대상이 될 다른 정보의 입수 가능성과 결합 가능성이 높아야 함
○ 예) 차량번호 : 자동차등록원부 등 다른 정보와 쉽게 결합하여 개인을 알아볼 수 있음
○ 만일 결합하는 데에 상당한 시간, 비용 등이 든다면 이는 개인정보에 해당하지 않음
개인정보의 종류
● 고유식별정보 : 개인을 고유하게 구별하기 위해 식별된 정보로, 일반개인정보와 구분⋅관리해야 함 (개인정보 보호법 제24조)
○ 주민등록번호, 여권번호, 운전면허번호, 외국인등록번호
● 민감정보 : 사상⋅신념, 노동조합⋅정당가입⋅탈퇴, 정치적 견해, 건강정보, 성생활 등에 관한 정보 (개인정보 보호법 제23조)
○ 건강정보 : 개인의 건강, 병력 등에 관한 정보
○ 생체정보 : 개인의 신체적, 생리적, 행동적 특징에 관한 정보 (개인정보 보호법 시행령 제18조)
○ 결제정보 : 입금내역, 결제기록 등의 금융 정보 (신용정보법, 전자상거래법 등)
● 개인위치정보 : 개인의 위치에 관한 정보 (위치정보법)
● 개인영상정보 : 영상정보 중 개인의 초상, 행동 등 개인을 식별할 수 있는 정보 (개인정보 보호법 제2조)

AI 윤리

(3-6) 데이터 전처리
: 데이터에 원하는 처리를 가하기 이전에 데이터를 가공 및 정제하는 과정
원천 데이터 구축 시 고려해야 할 품질 기준
- 기준 적합성
- 기술 적합성
- 통계적 다양성
도메인에 무관한 전처리
- 중복 데이터 처리
- 이상 데이터 처리
- 결측 데이터 처리
4. 데이터 라벨링
: 수집 및 전처리를 통해 획득한 원천 데이터를 구축 목적에 맞게 라벨/속성을 표기하는 작업


(4-1) 라벨링 가이드라인 작성 방법
필수 요소
- 데이터의 개요
- 용어 정의
- 어노테이션 절차
- 어노테이션 규칙 및 Edge Case
* 가이드라인은 처음부터 완성도 있게 만들어 업데이트되지 않도록 하는 것이 좋으며,
업데이트가 필요한 경우에는 해당 내용을 참고하여 변경 전의 데이터를 클렌징해야 함.
(4-2) 데이터 라벨링 규칙 설정 1 _ CV
이미지/영상 데이터를 입력으로 하는 라벨링 기법
● 바운딩 박스 (Bounding Box) / OCR (Optical Character Recognition, 광학 문자 인식)
: 각각의 객체/텍스트가 해당하는 위치를 직사각형 박스로 표기
● 큐보이드 (Cuboid; 3D Bounding Box)
● 폴리곤 (Polygon) : 바운딩 박스의 다각형 형태로, 보다 상세한 객체 라벨링을 위해 사용
● 폴리라인 (Polyline) : 선형 객체의 경계나 위치 등을 연속선으로 지정
● 의미 분할 (Semantic Segmentation; 시맨틱 분할) : 이미지의 각 픽셀을 라벨링
● 키포인트 (Keypoint) : 얼굴, 관절 등 객체의 주요 지점(특징)을 점으로 지정
(4-3) 데이터 라벨링 규칙 설정 2 _ NLP
텍스트 및 음성 데이터를 입력으로 하는 라벨링 기법
● 분류 및 태깅 ( 텍스트/음성 → 태그 )
○ 문서 전체 또는 특정 말뭉치의 라벨을 정하는 작업
● 전사 ( 음성 → 텍스트 )
○ 음성 데이터를 텍스트로 받아적는 작업
● 번역 및 요약 ( 텍스트 → 텍스트 )
○ 주어진 텍스트를 다른 텍스트로 변환하는 작업
(4-4) 라벨링 툴 소개
라벨링 툴 선정 시 고려 사항
● Quality Control : 일관성 있고 정확한 데이터를 생성할 수 있는지
● Efficiency : 시간을 단축하여 효율적으로 데이터를 쉽게 구축할 수 있는지
● Scalability : 여러 작업자가 동시에, 대규모 데이터를 처리할 수 있는지
대표적인 이미지 라벨링 툴
● COCO Annotator (무료)
● CVAT (Computer Vision Annotation Tool) (부분유료)
● Diffgram (대부분 무료)
● LabelImg (무료) Label Studio에 포함되면서 업데이트 중단
● LabelMe (무료)
● Scale AI (유료. 무료 평가판 제공)
● SuperAnnotate (부분유료)
● Supervisely (부분유료)
● VIA (VGG Image Annotator) (무료)
대표적인 텍스트 라벨링 툴
● Brat (무료)
● Doccano (무료)
● INCEpTION (무료) WebAnno의 후신
● LightTag (부분유료)
● Prodigy (유료)
● Tagtog (부분유료)
● Taguette (무료)
● UBIAI (유료)
5. 데이터 클렌징
(5-1) 데이터 클렌징
라벨링 에러의 종류
- 휴먼 에러
- 라벨링 규칙 에러
데이터 클렌징
: 위와 같은 라벨링 에러들을 수정하여 데이터의 품질을 향상시키는 것으로,
1) 예외가 많아 직접 클렌징(다시 라벨링) 해야 하는 경우와
2) 규칙 기반으로 코드를 통해 손쉽게 수정할 수 있는 경우로 나뉨
데이터 클렌징의 필요성
● 라벨링 에러는 노이즈이기 때문에 모델이 의도한 대로
동작하지 않거나, 모델의 성능이 저하될 수 있음
● 따라서 라벨링 에러가 존재하는 데이터를 제외시키거나
클렌징함으로써, 모델의 성능을 향상시킬 수 있음
● 반복적으로 발생하는 라벨링 에러의 경우에는 교육 또는
가이드라인에 업데이트하여 후속 작업에 반영할 수 있음
라벨링 에러 확인
● 샘플링 후 직접 검수
● 모델 결과 분석
● IAA 분석
● Confident Learning 활용
데이터 클렌징 방법
- 직접 클렌징 (다시 라벨링)
- 규칙 기반으로 코드를 통한 클렌징
(5-2) 데이터 평가 방법 _ IAA
IAA (Inter-Annotator Agreement)
: 동일한 작업에 할당된 작업자들 간의 일치 정도를 의미함, 범주형 또는 명목형 데이터에 주로 활용
Cohen’s Kappa
: Cohen’s Kappa(κ)는 범주형 변수를 평가하거나 분류할 때, 두 작업자 간의 일치 정도를 측정하는 메트릭

- Pr(a) : 작업자 사이에서 관찰된 상대적인 일치도
- Pr(e) : 각 작업자가 라벨을 무작위로 선택할 경우에 예상되는 작업자간 일치도
Fleiss Kappa
: 변주형 변수를 평가하거나 분류할 때, 세 명 이상의 작업자 간의 일치도를 측정하는 메트릭

(5-3) IAA를 활용한 데이터 클렌징 방법
● 작업의 난이도
● 데이터의 퀄리티
● 작업자의 실력
● 작업자들의 조합
● 라벨링 규칙
● 라벨링 가이드라인과 교육
이를 통해, IAA가 낮은 원인을 분석하여 데이터 클렌징에 활용
6. 데이터 마무리
(6-1) 데이터 스플릿
:데이터를 둘 또는 그 이상의 하위 세트로 나누는 것
● 2개의 파트로 나눈다면
○ 하나는 학습용(Training)으로
○ 또 다른 하나는 테스트용(Testing)으로 사용
● 3개의 파트로 나눈다면
○ 하나는 학습용(Training)
○ 다른 하나는 검증용(Validation)
○ 마지막 하나는 테스트용(Testing)으로 사용
데이터 스플릿의 목적 : 과적합 방지
데이터 스플릿을 하지 않는다면 unseen data를 가정하기 어렵고 어떤 모델이
unseen data에 잘 적합하는지 알 수 없음
모델이 unseen data에 대해 강건하지 않는다면 real world에서도 잘 적응할 거라
기대하기 어려움
(6-2) 합성 데이터 _ CV
합성 데이터의 목적
● 실제 데이터를 수집하거나 사용하는 것이 불가능하거나
적절치 않을 때 합성 데이터를 대신 사용
● 데이터 세트의 확장 및 보완, 학습 데이터의 양과 다양성을
늘려 모델의 성능 향상을 도모
● 실제 세계에서 관측하기 어려운 상황에 대한 시뮬레이션 및
통제 실험 (가설 검증 및 시나리오 연구)
● 개인 정보 보호 목적으로 사용
합성 데이터의 이점
● 실제 데이터 수집이 어렵거나 그 사용이 제한적인 경우에도 사용할 수 있음
● 데이터 수집 및 데이터 라벨링 비용을 줄이는 데 도움
○ 바탕이 되는 데이터가 있다면 해당 데이터의 라벨을 합성 데이터에도 사용할 수 있음
● 조명, 카메라 각도, 개체 배치, 배경 등의 요소를 정밀하게 제어 가능, 데이터 다양성 확보
○ 엣지 케이스 시뮬레이션 또는 특정 요구 사항을 맞추는 데 유용
● 개인 정보 보호 및 라이센스 문제 완화
합성 데이터의 한계
● 실제 데이터를 정확하게 표현하지 못할 수 있음
○ 현실 세계의 복잡성과 뉘앙스를 표현하는 것의 어려움
● 합성 데이터 생성에 사용한 모델과 가정에 의존적
○ 데이터에 대한 가정이 잘못됐을 경우, 결과물인 합성 데이터를 신뢰할 수 없음
● 일반화 문제, 데이터 과적합의 가능성
○ 합성 데이터가 실제 시나리오를 적절하게 나타내지 않을 경우 일반화의 어려움 존재
○ 합성 데이터의 시나리오에 대해 과적합될 수 있음
● Ground Truth가 없는 경우가 많은 합성 데이터의 특성 상 그 평가 및 검증에 어려움이 존재
합성 데이터의 다양한 활용
● 자율 주행
○ 자율 주행 시뮬레이션
● 로보틱스
○ 화물 적재 및 이동 시뮬레이션
● 결함 감지 및 품질 제어
○ 다수의 결함 케이스 생성, 품질 파악
● 의료 및 헬스케어
○ 개인 정보 보호, 의료 및 건강 지식 공유
● 소매업
○ 다수의 상품 이미지 생성, 식별률 향상
Generative Adversarial Networks (GANs)
Variational Autoencoder
Diffusion
3D Rendering
(6-4) 합성 데이터 _ NLP
자연어 처리(NLP) 합성 데이터의 목적
● 데이터 보충, 데이터가 적은 언어나 도메인에서 부족한 데이터를 보충하는 데 활용
○ 다국어 데이터 생성, 라벨링된 데이터가 부족한 언어나 방언 등의 데이터를 생성하는 데 유용
● 도메인 적용, 특정 스타일이나 도메인에 맞는 데이터 생성
○ 다양한 언어 구조 생성, 다양한 문장 구조, 어휘 및 언어 구조를 생성하는 데 도움
● 개인 정보 보호, 원 데이터와 유사하지만 개인 정보를 포함하지 않은 데이터 생성
자연어 처리(NLP) 합성 데이터의 한계
● 품질 관리
○ 합성 데이터의 품질이 높지 않을 수 있으며, 실제 언어를 대표하지 못할 수 있음
● 잠재 편향
○ 원본 데이터나 생성 모델에 존재하는 편향을 상속하거나 증폭할 수 있음
● 과적합
○ 실제 언어 패턴 보다는 그 생성 방법과 관련된 패턴에 과적합될 수 있음
● 윤리적 문제
○ 원본 데이터 및 모델의 윤리적 편향을 반영할 수 있음
○ 합성 데이터를 실제에 사용할 경우 윤리적 문제를 초래할 수 있음
RNN (Recurrent Neural Network)
BART (Bidirectional and Auto-Regressive Transformer)
LLM (Large Language Model)
(6-6) 액티브 러닝 (이론)
: 데이터 샘플링 방법의 일종으로, 모델 학습에 가장 유익한 데이터 지점을 점진적으로 선택하는 방법
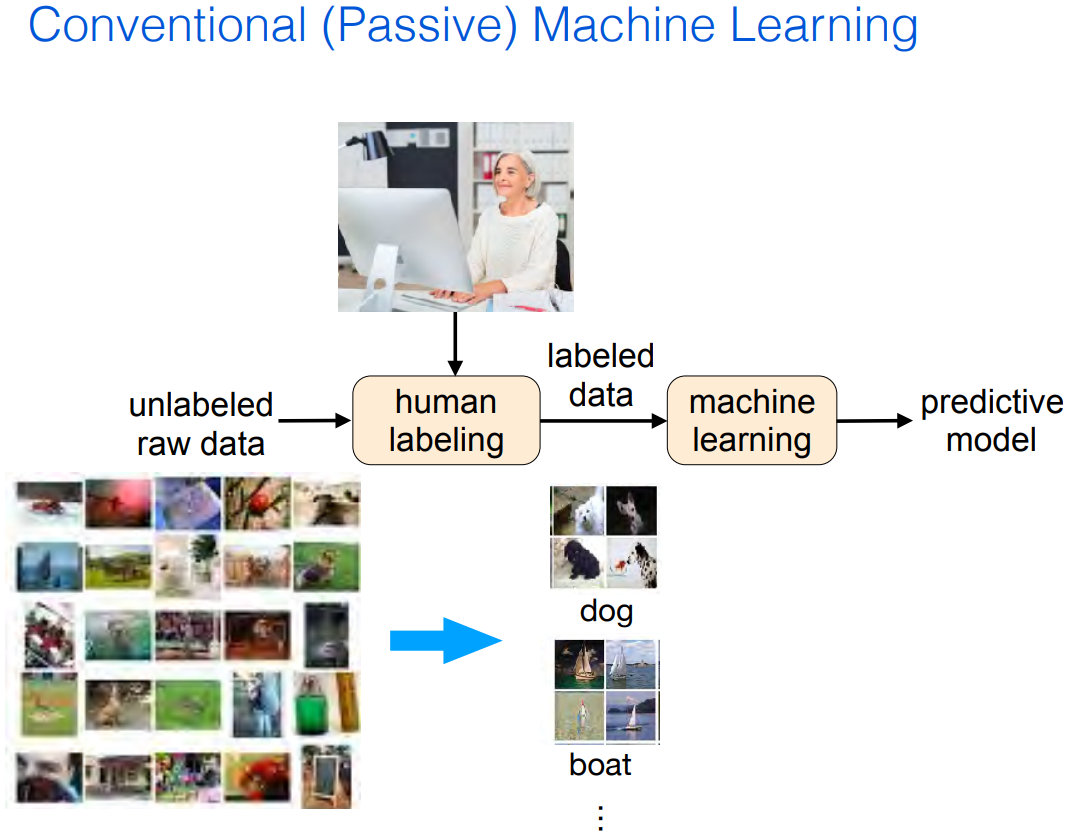 |
 |
참고 : https://icml.cc/media/icml-2019/Slides/4341.pdf
(6-8) 데이터 릴리즈
액티브 러닝의 효용
● 목표 성능에 도달하거나 성능을 향상시키는 데 필요한 데이터의 양을 줄여줌
● 리소스 효율적, 데이터 수집 예산 또는 라벨링 소요 시간에 관계 없이 리소스를 최대한 활용할 수 있게 해줌
● 가장 불확실하거나 유익한 데이터 포인트에 초점을 맞춤으로써 unseen 데이터에 대해 효과적으로 일반화하는 모델을 만들 수 있음
액티브 러닝 유스 케이스
● 데이터 예산이 제한된 경우, 액티브 러닝을 통해 유익한 데이터를 샘플링 한 후 해당 데이터만 라벨링 수행
● 데이터 세트가 불균형한 경우, 클래스 희소성으로 인한 편향 완화
● 기존의 샘플링 방식이 모델 정확도나 목표 지표를 향상시키지 못했을 경우, 액티브 러닝은 그 대안이 될 수 있음
액티브 러닝의 한계
● 라벨링된 초기 데이터가 필요, 초기 데이터 세트를 얻는 것이 리소스 집약적일 수 있음
● 라벨링을 완전히 배제하지 않아 작업자의 라벨링에 많은 시간과 비용이 소요될 수 있음
● 모델 의존적, 모델이 불확실성을 올바르게 추정하지 못하는 경우 라벨링에 유익하지 않은 예를 선택할 수 있음
● 사이클 반복에 시간이나 계산 비용이 많이 소요될 수 있음
액티브 러닝 샘플링
Uncertainty Sampling
: 결정 경계(Decision boundary)와 가까운 불확실한 데이터 포인트를 샘플링하는 방법
Cluster-based Sampling
: 데이터를 여러 개의 클러스터로 묶은 다음 샘플링하는 방법
Query-by Committee
: 여러 개의 모델로 위원회(Committee)를 구성한 후, 가장 불일치하는 데이터 포인트를 샘플링하는 방법
AI 미래 방향은 DATA DATA DATA!!!