강사 : 김용담
- 서강대학교 컴퓨터공학과 학사, 석사
- 패스트캠퍼스 전속강사
- Kaggle Competition & Notebook Expert
- 데이터사이언스 관련 강의 5000시간 이상
목차
1) numpy
2) pandas
3) seaborn
4) EDA
▣ Numpy
Numerical computing with Python. 수치연산 및 벡터 연산에 최적화된 라이브러리.
- 2005년에 만들어졌으며, 100% 오픈소스입니다.
- 최적화된 C code로 구현되어 있어 엄청나게 좋은 성능을 보입니다.
- 파이썬과 다르게 수치 연산의 안정성이 보장되어 있습니다. (numerical stable)
- N차원 실수값 연산에 최적화되어 있습니다. == N개의 실수로 이루어진 벡터 연산에 최적화되어 있습니다.
Numpy를 사용해야 하는 이유
- 데이터는 벡터로 표현됩니다. 데이터 분석이란 벡터 연산입니다. 그러므로 벡터 연산을 잘해야 데이터 분석을 잘할 수 있습니다.
- (native) 파이썬은 수치 연산에 매우 약합니다. 실수값 연산에 오류가 생기면 (numerical error) 원하는 결과를 얻지 못할 수 있습니다. 많은 실수 연산이 요구되는 머신러닝에서 성능 저하로 이어질 수 있습니다.
- numpy는 벡터 연산을 빠르게 처리하는 것에 최적화되어 있습니다. 파이썬 리스트로 구현했을 때보다 훨씬 더 높은 속도를 보여줍니다.
1. Numpy Array and Operation
numpy array의 특징
- 모든 원소의 dtype이 같다.
- 연산의 의미가 조금 다르다. (broadcasting)
- 대용량 array인 경우에 for문을 직접 사용하는 것보다 내부적으로 정의된 연산을 사용하는게 더 빠르다.
- 생성 후에 크기 변경이 불가능하다.
# numpy 라이브러리
import numpy as np
# version 확인
np.__version__
# 파이썬 리스트 선언
data = [1,2,3,4]
# 파이썬 2차원 리스트(행렬) 선언
data2 = [[1,2],
[3,4]]
- numpy array로 변환(1차원)
np.array(data)
실행)
array([1, 2, 3, 4])- 2차원 리스트를 np.array
np.array(data2)
출력)
array([[1, 2],
[3, 4]])
1. numpy array 생성방법
np.arange(0,10)
np.arange(0,10).shape # (10,) - 1차원 numpy array
np.zeros(shape=(5,)) # array([0., 0., 0., 0., 0.])
np.zeros(shape=(5,3))
# array([[0., 0., 0.],
# [0., 0., 0.],
# [0., 0., 0.],
# [0., 0., 0.],
# [0., 0., 0.]])
np.linspace(0,1,10) # 특정구간의 갯수만큼 균등 숫자 생성
# [start, stop]에서 num개의 number를 균등한 구간으로 잘라서 원소를 생성
# array([0. , 0.11111111, 0.22222222, 0.33333333, 0.44444444,
# 0.55555556, 0.66666667, 0.77777778, 0.88888889, 1. ])
np.random.randn(5,3)
# # Return a sample (or samples) from the "standard normal" distribution.(표준정규분포)
# array([[-1.59359743, -0.62665787, -1.22097732],
# [ 0.89072018, 0.78366209, 0.35240815],
# [ 1.15542566, 0.67757696, 0.61264326],
# [ 1.05803722, -2.14297234, -0.84047931],
# [ 0.0856095 , -3.09546886, -0.25720783]])
2. Reshaping array
# 1차원 : vector
# 2차원 : matrix
# 3차원 이상 : tensor
# shape은 가장 바깥 괄호부터 원소의 개수를 순차적으로 기록한 것으로 정의.
p.zeros(shape=(5,3,4))
# array([[0., 0., 0.],
# [0., 0., 0.],
# [0., 0., 0.],
# [0., 0., 0.],
# [0., 0., 0.]])
# 224 x 224 크기의 3개(RGB)의 channel을 가지고 있는 이미지가 32개.
np.zeros(shape=(32,3,224,224))
# reshape
np.arange(1,10).reshape(3,3)
np.arange(1,121).reshape(24, -1) # -1 알아서 계산해 나눠 준다.
np.arange(1,121).reshape(-1, 8)
3. Concatenation Arrays
더하기
arr1 = np.array([1, 2, 3])
arr2 = np.array([4, 5, 6])
arr1 + arr2
# array([5, 7, 9])
연결하기
np.vstack([arr1, arr2]) # 세로
# array([[1, 2, 3],
# [4, 5, 6]])
np.hstack([arr1, arr2]) # 가로
# array([1, 2, 3, 4, 5, 6])
4. Array 연산
v1 = np.array((1,2,3))
v2 = np.array((4,5,6))
v1 + v2
# array([5, 7, 9])
v1 - v2
# array([-3, -3, -3])
v1 * v2
# array([ 4, 10, 18])
v1 / v2
# array([0.25, 0.4 , 0.5 ])
v1 @ v2
# 32
5. Broadcasting, universal Function
서로 크기가 다른 numpy array를 연산할 때, 자동으로 연산을 전파(broadcast)해주는 기능
arr1 = np.array([1,2,3])
arr2 = np.array([[-1,-1,-1],
[1, 1, 1]])
arr1 + arr2 # (3,) + (2,3) 크기가 같은 마지막 차수 것을 찾아 broadcasting
# array([[0, 1, 2],
# [2, 3, 4]])
######################################
# (3,) + (3, 2) 는 계산 오류남.
# (5,) + (3,4,5) : 가능
# (3,4) + (5,3,4) : 가능
# (3,4) + (3,4,5) : 불가
arr1 * arr2
# array([[-1, -2, -3],
# [ 1, 2, 3]])
# universal Function
arr1 / 1 # int -> float dtype변경 트릭으로 사용
# array([1., 2., 3.])
# Universal Function
1 / arr1 # 각 원소를 reverse연산. array([1. , 0.5 , 0.33333333])
# => 아래와 같다.
arr1 = np.array([1.,2.,3.])
def reverse_num(x):
return 1/x
for i in range(len(arr1)):
arr1[i] = reverse_num(arr1[i])
arr1
# array([1. , 0.5 , 0.33333333])
6. Numpy method
- math
# pseudo-random(sw에서는 완벽한 random을 구현할 수 없어서...) : 현재 시간(ns)을 기준으로
np.random.seed(42) # 고정된 랜덤을 생성하기 위해 seed번호 설정
mat1 = np.random.randn(5,3)
mat1
# array([[ 0.49671415, -0.1382643 , 0.64768854],
# [ 1.52302986, -0.23415337, -0.23413696],
# [ 1.57921282, 0.76743473, -0.46947439],
# [ 0.54256004, -0.46341769, -0.46572975],
# [ 0.24196227, -1.91328024, -1.72491783]])
# 절대값
np.abs(mat1)
# array([[0.49671415, 0.1382643 , 0.64768854],
# [1.52302986, 0.23415337, 0.23413696],
# [1.57921282, 0.76743473, 0.46947439],
# [0.54256004, 0.46341769, 0.46572975],
# [0.24196227, 1.91328024, 1.72491783]])
# 제곱근
np.sqrt(mat1)
# array([[0.70477951, nan, 0.80479099],
# [1.23411096, nan, nan],
# [1.25666734, 0.87603352, nan],
# [0.73658675, nan, nan],
# [0.49189661, nan, nan]])
- 집계
np.random.seed(0xC0FFEE) # 김용담 강사가 좋아하는 숫자
mat2 = np.random.rand(3, 2) # 0과 1사이 값.
mat2
array([[0.57290783, 0.81519505],
[0.92585076, 0.09358959],
[0.26716135, 0.96059676]])
np.sum(mat2)
np.sum(mat2, axis=0) # 세로방향(=같은column) 합
np.sum(mat2, axis=1) # 가로방향(=같은row) 합
np.mean(mat2, axis=0)
np.std(mat2, axis=1)
np.min(mat2)
np.max(mat2, axis=1)
# 최대값이 있는 Index
np.argmax(mat2, axis=0)
# numpy dtype (number representation)
print(f"int4 : -{2**3} ~ {2**3 - 1}")
print(f"int8 : -{2**7} ~ {2**7 - 1}")
print(f"int16 : -{2**15} ~ {2**15 - 1}")
print(f"int32 : -{2**31} ~ {2**31 - 1}")
print(f"int64 : -{2**63} ~ {2**63 - 1}")
# int4 : -8 ~ 7
# int8 : -128 ~ 127
# int16 : -32768 ~ 32767
# int32 : -2147483648 ~ 2147483647
# int64 : -9223372036854775808 ~ 9223372036854775807
▣ Pandas
Library 불러오기
import pandas as pd
pd.__version__
1. DataFrame
# 12x4 행렬, index는 0부터 시작하고, coulmns은 순서대로 X1, X2, X3, X4로 하는 DataFrame 생성
np.random.seed(42)
df = pd.DataFrame(data=np.random.randn(12,4),
index=np.arange(12),
columns=['X1', 'X2', 'X3', 'X4'])
# dataframe index
df.index
# dataframe columns
df.columns
# 문자열 dtype='object'
df.values # DataFrame의 데이터를 np.array로 가져옴.
# 특정 column을 가져오기
df['X1']
# X1 column에 2 더하기
df['X1'] + 2 # broadcasting - numpy와 같다
2. Method
# dataframe의 맨 위 다섯줄을 보여주는 head()
df.head()
# 10줄
df.head(10)
# 뒤에서 부터 기본 5줄
df.tail()
# dataframe에 대한 전체적인 요약정보. index, columns, null/not-null/dtype/memory usage 표시.
df.info()
# dataframe에 대한 전체적인 통계정보
df.describe()
# X2 column를 기준으로 내림차순 정렬
df.sort_values(by='X2', ascending=False)
3. 팬시 인덱싱
# dataframe에 조건식을 적용해주면 조건에 만족하는지 여부를 알려주는 "mask"가 생깁니다.
# df에서 X3 column에 있는 원소들중에 양수만 출력하기
mask = df['X3'] > 0 ## boolean mask
df[ mask ] ## boolean mask를 DataFrame에 indexing을 하면 True에 해당하는 위치의 row들이 뽑힘.
df[ mask ] ['X3'] # 방법 1
## df.loc[row에 대한 조건식, col에 대한 조건식]
df.loc[mask, 'X3'] # 방법 2
##df에서 X1 column에 있는 원소들중에서 1보다 작은 원소들을 출력.
mask = df['X1'] < 1
df.loc[mask, 'X1']
# iloc로 2차원 indexing을 하게되면, row 기준으로 index 3,4를 가져오고 column 기준으로 0, 1을 가져옴.
df.iloc[[3,4],[0, 1]]
# 2차원 indexing에 뒤에가 :
df.iloc[:, 3] # df['X4'] 와 같음
df.iloc[0, :] # 0 row
4. 데이터프레임 합치기
df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']},
index=[0, 1, 2, 3])
df2 = pd.DataFrame({'A': ['A4', 'A5', 'A6', 'A7'],
'B': ['B4', 'B5', 'B6', 'B7'],
'C': ['C4', 'C5', 'C6', 'C7'],
'D': ['D4', 'D5', 'D6', 'D7']},
index=[4, 5, 6, 7])
df3 = pd.DataFrame({'A': ['A8', 'A9', 'A10', 'A11'],
'B': ['B8', 'B9', 'B10', 'B11'],
'C': ['C8', 'C9', 'C10', 'C11'],
'D': ['D8', 'D9', 'D10', 'D11']},
index=[8, 9, 10, 11])
# 위-아래로 그냥 합치기 (concatenation)
pd.concat([df1, df2, df3]) # axis=0, column을 기준으로 세로방향 합치기
pd.concat([df1, df2, df3], axis=1) # index를 기준으로 가로방향 합치기
df2.reset_index(drop=True) # VIEW - 원본에 적용되지 않음
# drop=True 기존 인덱스 삭제
# index를 맞춰 수정한 후 index를 기준으로 가로방향 합치기
pd.concat([df1, df2.reset_index(drop=True), df3.reset_index(drop=True)], axis=1)
# data와 인덱스 수정 .....
df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
df2 = pd.DataFrame({'A': ['A4', 'A5', 'A1', 'A2'],
'B': ['B4', 'B5', 'B6', 'B7'],
'C': ['C4', 'C5', 'C6', 'C7'],
'D': ['D4', 'D5', 'D6', 'D7']})
df3 = pd.DataFrame({'A': ['A8', 'A9', 'A10', 'A11'],
'B': ['B8', 'B9', 'B10', 'B11'],
'C': ['C6', 'C7', 'C10', 'C11'],
'D': ['D8', 'D9', 'D10', 'D11']})
# A inner join B --> table A와 table B의 특정 column에서 겹치는 값들을 기준으로 두 테이블을 합치는 연산.
pd.merge(left=df1,
right=df2,
on='A',
how='inner')
# A B_x C_x D_x B_y C_y D_y
# 0 A1 B1 C1 D1 B6 C6 D6
# 1 A2 B2 C2 D2 B7 C7 D7
#df2 inner join df3 (column C)
pd.merge(left=df2, right=df3, on='C', how='inner')
# A_x B_x C D_x A_y B_y D_y
# 0 A1 B6 C6 D6 A8 B8 D8
# 1 A2 B7 C7 D7 A9 B9 D9
# left join : left table(df1)을 기준으로 right table(df2)에서 on에 대해서 겹치는 대상을 붙여준다.
# 겹치지 않는 데이터는 NaN으로 추가한다.
pd.merge(df1, df2, on='A', how='left')
# A B_x C_x D_x B_y C_y D_y
# 0 A0 B0 C0 D0 NaN NaN NaN
# 1 A1 B1 C1 D1 B6 C6 D6
# 2 A2 B2 C2 D2 B7 C7 D7
# 3 A3 B3 C3 D3 NaN NaN NaN
데이터 불러오기 with DataFrame
titanic = pd.read_csv('train.csv')
# 여성 승객들의 평균 나이
# 넘파이 함수
np.mean(titanic.loc[titanic.Sex == 'female', 'Age'])
# 판다스 자체 함수
titanic.loc[titanic.Sex == 'female', 'Age'].mean()
#1등석에 탑승한 승객 중 최대 요금을 낸 사람의 이름.
# titanic.Pclass == 1
# 방법1 : 내풀이
max_fare = titanic.loc[titanic.Pclass == 1, 'Fare'].max()
# titanic.loc[titanic['Fare'] == max_fare]['Name']
titanic.loc[titanic['Fare'] == max_fare, 'Name']
# 방법2
temp = titanic.loc[titanic.Pclass == 1, ['Name', 'Fare']]
temp.loc[temp.Fare == temp.Fare.max(), "Name"]
# 1등석에 탑승한 승객 중 승선한 곳이 (Embarked ) Queenstown인 사람의 수
# 내 풀이
titanic.loc[(titanic.Pclass == 1) & (titanic.Embarked == 'Q'), ['Name']].count()
# 강사풀이
titanic[(titanic.Pclass == 1) & (titanic.Embarked == 'Q')]
# mask & mask : 두 조건을 둘 다 만족하는 mask (AND)
# mask | mask : 두 조건 중 하나 이상 만족하는 mask. (OR)
# ~mask : 조건을 반전 (NOT)
#승선한 곳이 "S"인 사람들의 생존자 수
titanic.loc[titanic.Embarked.isin(['S']), 'Survived'].sum() # 1이 생존자이므로
#미혼 여성중에 나이값이 모르는 사람의 수
# contains 정규 표현식 사용가능
titanic.loc[titanic.Name.str.contains("Miss."),'Age'].isnull().sum()
boolean mask 주의 사항
주의) boolean mask는 무조건 mask와 적용 대상의 index가 같아야 한다.
5. Pivot Table
# 성별을 기준으로 생존률 파악 --> Mean vs Sum
pd.pivot_table(data=titanic, index='Sex', values='Survived', aggfunc='mean')
# Survived
# Sex
# female 0.742038
# male 0.188908
# 사회 계급을 기준으로 생존률 파악
pd.pivot_table(data=titanic, index='Pclass', values='Survived', aggfunc=['count', 'sum', 'mean'])
# count sum mean
# Survived Survived Survived
# Pclass
# 1 216 136 0.629630
# 2 184 87 0.472826
# 3 491 119 0.242363
pd.pivot_table(data=titanic, index=['Sex', 'Pclass'], values='Survived', aggfunc=['count', 'sum', 'mean'])
# count sum mean
# Survived Survived Survived
# Sex Pclass
# female 1 94 91 0.968085
# 2 76 70 0.921053
# 3 144 72 0.500000
# male 1 122 45 0.368852
# 2 108 17 0.157407
# 3 347 47 0.135447
▣ Seaborn
Library import
import seaborn as sns
sns.__version__from seaborn import load_dataset
data = load_dataset('penguins').dropna() # NaN이 하나라도 포함된 row가 있다면 제외.
Histplot
- 가장 기본적으로 사용되는 히스토그램을 출력하는 plot.
- 전체 데이터를 특정 구간별 정보를 확인할 때 사용.
- 수치형 데이터(연속형)의 대략적인 분포를 확인할 때 사용.
- 구간별 count를 계산해서 막대로 표현하는 그래프.
# penguin 데이터에 histplot을 출력합니다.
import matplotlib.pyplot as plt
# seaborn 그래프 그리기 전 - seaborn이 덮어 그릴 수 있기 때문에 주의
plt.figure(figsize=(8,5))
plt.title("Bill Length", fontsize=16, loc='left')
sns.histplot(data=data, x='bill_length_mm', bins=30, hue='species', multiple='stack', palette='Spectral')
# 펭귄 부리 길이 bill_length_mm
# bins : 구간의 갯수 = 막대 갯수
# hue : 특성기준별로 색상 달리함
# multiple : 막대그래프 합치기
# pallete : Blues(단일색상), Set2(discrete-서로 색상이 비교적 다른 편),viridis, Spectral(continuous-연속적으로 색상표현)
# => 김용담강사 자주사용 color palette name들
# seaborn 그래프 그리기고 난 후
plt.xlabel('Bill Length')
plt.ylabel('Number of Penguins')
# plt.xlim(45, 60) # x축 제한
# plt.xticks([n*10 for n in range(7)])
plt.show()
distplot
# penguin 데이터에 displot을 출력. kde:밀도(겹치는 걸 볼 때 잘보임), ecdf:누적확률분포
sns.displot(data=data, x="flipper_length_mm", kind='hist', col='island', row='sex', hue='species', multiple='stack')
barplot
sns.barplot(data=data, x='species', y='body_mass_g', errorbar=None)
# 기본 body_mass_g 평균, errorbar=None : 오차 표시 없애기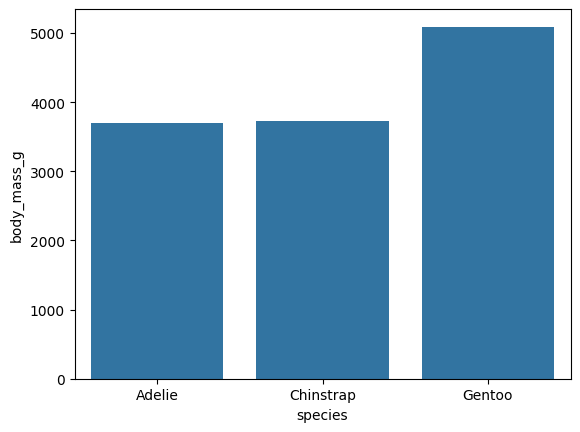
plt.figure(figsize=(12,4))
# x, y 값을 바꾸면 가로방향 막대 그래프 표시됨
sns.barplot(data=data, x='body_mass_g', y='species', errorbar=None, hue='species', palette='Set2')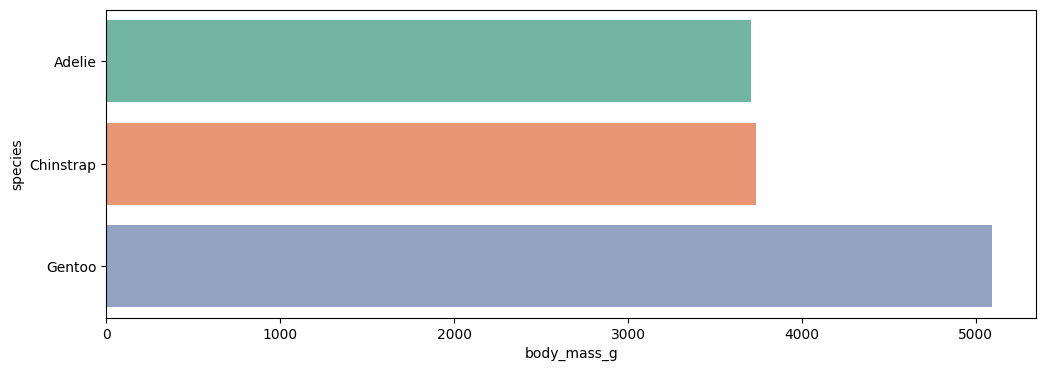
countplot
sns.countplot(data=data,x='species') # 연속형 변수에는 사용하지 않는다.
boxplot
sns.boxplot(data=data, x='species', y='body_mass_g')
# Inter-Quartile-Range
# IQR = q75 - q25
# lower_bound = q25 - IQR * 1.5
# upper_bound = q75 + IQR*1.5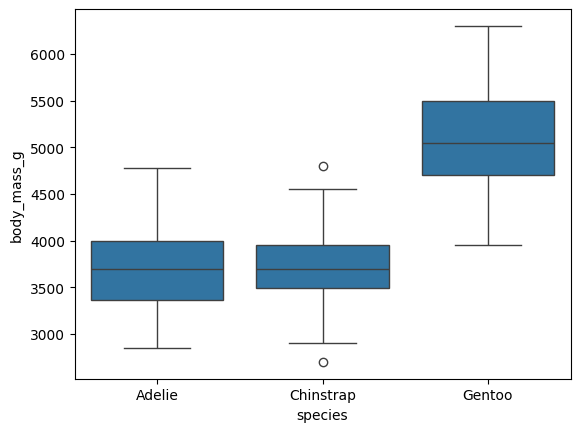
scatterplot
sns.scatterplot(data=data, x='bill_length_mm', y='flipper_length_mm', hue='species')
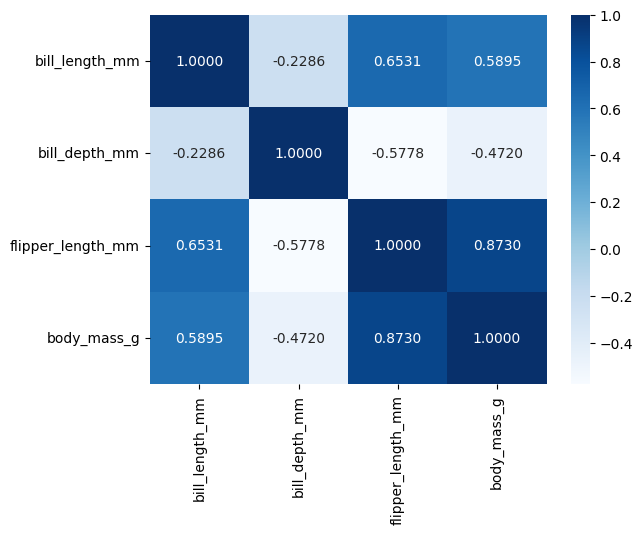
heatmap
corr = data.corr(numeric_only=True) # str 에러 날 때 numeric_only=True
sns.heatmap(data=corr, annot=True, fmt='.4f', cmap='Blues') # annot=True 숫자 표시