NLP 학습과정은 크게 Basic, Advanced, 경진대회, 그리고 LM to LLM으로 이어진다.
학습목표는 아래와 같다.
-. 자연언어처리(Natural Language Processing, NLP)에 대한 깊이 있는 이해, 자연어처리 응용 분야와 연구 동향
-. 규칙기반, 통계기반, 기계학습, 딥러닝, Attention 및 Transformer 등 다양한 방법론등의 자연언어처리의 기본적인 개념과 이론을 학습하고 이해하는 것
-. 자연언어처리의 다양한 응용분야와 LLM 등의 최신 연구 동향을 파악, 이를 통해 미래의 자연언어처리 기술 및 응용에 대한 통찰력을 기르는 것
NLP관련 학습내용과 경진대회를 간단히 정리해 보고자 한다.
NLP Basic
1. 자연언어처리
2. 자연언어처리를 위한 언어학 기초
3. 자연언어처리의 시작: 텍스트 전처리
4. 자연언어처리의 다양한 응용시스템
5. 자연언어처리의 역사 A to Z
6. 딥러닝 기반 자연언어처리
1. 자연언어처리
: 컴퓨터가 자연언어의 의미를 분석하고 이해하고 생성할 수 있도록 만들어 주는 기술


자연어 처리의 어려움
중의성, 고유명사(연예인 이름과 보통명사), 사전 미등록언어(신조어)

한국어 처리가 어려운 이유

나는 밥을 먹으러 간다.
밥을 먹으러 나는 간다.
나는 간다. 밥을 먹으러


2. 자연언어처리를 위한 언어학 기초

음절, 품사, 형태소


품사


3. 자연언어처리의 시작: 텍스트 전처리
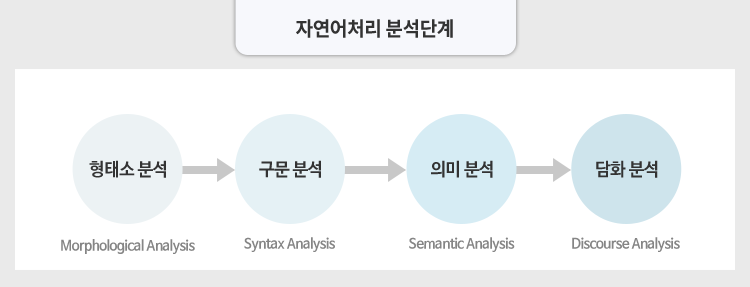
컴퓨터가 텍스트를 이해할 수 있도록 하는 Data preprocessing 방법
- HTML 태그, 특수문자, 이모티콘
- 정규표현식
- 불용어
- 어간추출
- 표제어 추출

4. 자연언어처리의 다양한 응용시스템
Text Classification
Information Extraction
Machine Translation/Diallogue System/Document Summerization
Machine Reading Comprehension/Question Answering
5. 자연언어처리의 역사 A to Z
 |
 |
https://medium.com/@antoine.louis
6. 딥러닝 기반 자연언어처리

Sequence to Sequence

RNN


Self-Attention


NLP Advanced
1. 자연어 처리 Task 이해하기
2. 자연어 처리 Pipeline 이해하기
3. Transfer Learning
1. 자연어 처리 Task 이해하기
1) Huggingface
기계학습을 사용하여 애플리케이션을 구축하기 위한 도구를 개발하는 미국회사
2) 자연어 처리 Task들
● 기계 번역 : 다양한 국가의 언어를 원하는 타겟 언어로 번역
● 질의 응답 : 사용자의 질문을 이해하고 관련 문서를 찾아 올바른 정답을 추출하거나 내재된 지식을 통해 생성
● 정보 추출 : 주어진 쿼리를 기반으로 관련 문서, 정보들을 추출
● 감성 분류 : 주어진 입력 문장의 감성 (긍정, 부정, 중립) 을 분류
● 요약 : 주어진 본문의 중요한 내용을 요약
영화리뷰 감성분류하기
뉴스본문 요약하기
3) 자연어 처리 평가지표(Evaluation Metrics)
BLEU (Bilingual Evaluation Understudy Score)
: 기계번역 (NMT)이나 텍스트 생성 (Text Generation) 작업의 품질을 평가할때 사용되는 평가지표 (metrics)
2. 자연어 처리 Pipeline 이해하기
1) 파이프라인 전체 구조
- 환경설정 : 라이브러리 설치 및 데이터셋 로드 (train.csv, test.csv)
- 데이터셋 구축 : 입력 데이터 (Input data)를 train/valid = 7.5:2.5로 나눠준 (split)후 토크나이징 (Tokenizing)하여 torch dataset class 로 변환
- 모델 및 토크나이저 가져오기 : Huggingface 의 사전학습된 (Pre-trained) 모델 로드 (load)
- 모델 학습 : Huggingface 의 TrainingArguments & Trainer 를 활용하여 학습데이터 (train data)로 모델 학습
- 추론 및 평가 : 학습된 (Fine-tuned) 모델을 통해 평가 데이터 (Test data) 추론 및 평가 (Evaluation)진행
3. Transfer Learning
딥러닝의 발전
단어 임베딩(Word2vec, GloVe)를 통해 단어를 벡터로 표현하여 컴퓨터가 자연어를 이해하도록 함.
딥러닝 모델(CNN, RNN, LSTM)을 통해 자연어를 처리하는 기술들이 급격히 성장함.
Transfer Learning
특정한 도메인 task로 부터 학습된 모델을 비슷한 도메인 task 수행에 재사용하는 기법
Transfer Learning in CV
ImageNet과 같은 많은 양의 이미지 데이터로 부터 사전학습 수행
미리 학습된 파라미터를 이미지 분류, 객체인식과 같이 풀고자 하는 task에 사용되는 모델에 적용하여 학습된 정보를 전이시킴
Transfer Learning in NLP

ELMo (Embeddings from Language Models)

4. Decoder only 구조의 GPT
● GPT-1
Transfer learning 패러다임을 적용하여 Pre-training 모델 기반으로 원하는 하나의 task 에 Fine-tuning 하여 모델 학습
● GPT-2
Multi-Task learning 과 유사하게 여러가지 task 를 수행 가능한 하나의 일반화된 모델 학습
● GPT-3
큰 크기의 모델 하나로 여러 task 를 수행할 수 있도록 In-context learning 을 통해 task 별 Few-shot 예제만으로 성능
향상
5. Encoder-Decoder 구조의 BART
● Encoder-Decoder 구조의 강점
Source 문장의 정보를 압축하는 Encoder 와 이 정보를 받아 다음 단어를 생성하는 Decoder 가 함께 있는 구조로, seq2seq
task 수행에 특화된 모델 구조
● Noise 를 추가하는 Pre-training 방식
Token Masking, Token Deletion, Text Infilling, Sentence Permutation, Document Rotation 를 통해 noise 추가하는
방식으로 Pre-training
6. BERT 이후의 인코더 기반 사전학습 언어 모델
● RoBERTa : 동적 마스킹 방식을 적용하여 MLM 을 수행하는 모델
● SpanBERT : Span 마스킹 방식을 적용하여 MLM 을 수행하는 모델
● ELECTRA : GAN 과 유사한 구조로 변형된 MLM 을 수행하는 모델
● ALBERT : 모델 경량화를 위해 파라미터 수를 크게 축소한 모델
● DistilBERT : 대형 모델로부터 학습된 정보를 전이시켜 사전 학습을 수행하는 모델
7. NLP 최신 트렌드
● Scaling Laws
모델의 성능에 영향을 주는 요인에 대해 파악하고, 모델 크기, 데이터 크기와 컴퓨팅 능력을 적절히 확장하면 언어 모델링
성능을 예측 가능하게 향상시킬 수 있음.
● RLHF
사람이 좀 더 선호하는 응답을 바탕으로 강화학습함으로써 다양한 task 에 대해 사용자의 의도를 따르도록 큰 모델을
학습하는 기법.
● Prompt Engineering
여러 task 를 수행가능한 하나의 모델은 입력되는 Prompt 에 따라 결과의 차이를 보임.
좋은 Prompt 를 작성하는 가이드 제안.
Upstage NLP 경진 대회
▣ 대회 주제
Dialogue Summarization | 일상 대화 요약
학교 생활, 직장, 치료, 쇼핑, 여가, 여행 등 광범위한 일상 생활 중 하는 대화들에 대해 요약합니다.
▣ 대회 개요
Dialogue Summarization 경진대회는 주어진 데이터를 활용하여 일상 대화에 대한 요약을 효과적으로 생성하는 모델을 개발하는 대회입니다.
일상생활에서 대화는 항상 이루어지고 있습니다. 회의나 토의는 물론이고, 사소한 일상 대화 중에도 서로 다양한 주제와 입장들을 주고 받습니다. 나누는 대화를 녹음해두더라도 대화 전체를 항상 다시 들을 수는 없기 때문에 요약이 필요하고, 이를 위한 통화 비서와 같은 서비스들도 등장하고 있습니다.
그러나 하나의 대화에서도 관점, 주제별로 정리하면 수 많은 요약을 만들 수 있습니다. 대화를 하는 도중에 이를 요약하게 되면 대화에 집중할 수 없으며, 대화 이후에 기억에 의존해 요약하게 되면 오해나 누락이 추가되어 주관이 많이 개입되게 됩니다.
이를 돕기 위해, 우리는 이번 대회에서 일상 대화를 바탕으로 요약문을 생성하는 모델을 구축합니다!
참가자들은 대회에서 제공된 데이터셋을 기반으로 모델을 학습하고, 대화의 요약문을 생성하는데 중점을 둡니다. 이를 위해 다양한 구조의 자연어 모델을 구축할 수 있습니다.
제공되는 데이터셋은 오직 "대화문과 요약문"입니다. 회의, 일상 대화 등 다양한 주제를 가진 대화문과, 이에 대한 요약문을 포함하고 있습니다.
참가자들은 이러한 비정형 텍스트 데이터를 고려하여 모델을 훈련하고, 요약문의 생성 성능을 높이기 위한 최적의 방법을 찾아야 합니다.
경진대회의 목표는 정확하고 일반화된 모델을 개발하여 요약문을 생성하는 것입니다. 나누는 많은 대화에서 핵심적인 부분만 모델이 요약해주니, 업무 효율은 물론이고 관계도 개선될 수 있습니다. 또한, 참가자들은 모델의 성능을 평가하고 대화문과 요약문의 관계를 심층적으로 이해함으로써 자연어 딥러닝 모델링 분야에서의 실전 경험을 쌓을 수 있습니다.
본 대회는 결과물 csv 확장자 파일을 제출하게 됩니다.
input : 249개의 대화문
output : 249개의 대화 요약문
▣ 평가방법
Dialogue Summarization task에서는 여러 인물들이 나눈 대화 내용을 요약하는 문제입니다. 예측된 요약 문장을 3개의 정답 요약 문장과 비교하여 metric의 평균 점수를 산출합니다. 본 대회에서는 ROUGE-1-F1, ROUGE-2-F1, ROUGE-L-F1, 총 3가지 종류의 metric으로부터 산출된 평균 점수를 더하여 최종 점수를 계산합니다.
3개의 정답 요약 문장의 metric 평균 점수를 활용하기에 metric 점수가 100점이 만점이 아니며, 3개의 정답 요약 문장 중 하나를 랜덤하게 선택하여 산출된 점수가 약 70점 정도임을 말씀드립니다.
ROUGE는 텍스트 요약, 기계 번역과 같은 태스크를 평가하기 위해 사용되는 대표적인 metric입니다. 모델이 생성한 요약본 혹은 번역본을 사람이 만든 참조 요약본과 비교하여 점수를 계산합니다.
- ROUGE-Recall: 참조 요약본을 구성하는 단어들 중 모델 요약본의 단어들과 얼마나 많이 겹치는지 계산한 점수입니다.
- ROUGE-Precision: 모델 요약본을 구성하는 단어들 중 참조 요약본의 단어들과 얼마나 많이 겹치는지 계산한 점수입니다.
ROUGE-N과 ROUGE-L은 비교하는 단어의 단위 개수를 어떻게 정할지에 따라 구분됩니다.
- ROUGE-N은 unigram, bigram, trigram 등 문장 간 중복되는 n-gram을 비교하는 지표입니다.
- ROUGE-1는 모델 요약본과 참조 요약본 간에 겹치는 unigram의 수를 비교합니다.
- ROUGE-2는 모델 요약본과 참조 요약본 간에 겹치는 bigram의 수를 비교합니다.
- ROUGE-L: LCS 기법을 이용해 최장 길이로 매칭되는 문자열을 측정합니다. n-gram에서 n을 고정하지 않고, 단어의 등장 순서가 동일한 빈도수를 모두 세기 때문에 보다 유연한 성능 비교가 가능합니다.
ROUGE-F1은 ROUGE-Recall과 ROUGE-Precisioin의 조화 평균입니다.

▣ 세부일정
프로젝트 전체 기간 (2주) : 8월 29일 (목) 10:00 ~ 9월 10일 (화) 19:00
GPU 서버 운영 기간 : 8월 29일 (목) 10:00 ~ 10월 1일 (화) 16:00
▣ 데이터 개요
모든 데이터는 .csv 형식으로 제공되고 있으며, 각각의 데이터 건수는 다음과 같습니다.
train : 12457
dev : 499
test : 250
hidden-test : 249
▣ 프로젝트 진행
우리팀(5팀)은 boilerplate 템플릿을 기반으로 대회를 진행하고자 의사결정을 하였고,
팀장 박석님이 PyTorch Ignite을 Template코딩을 하였다.
하지만 대회 중반까지도 에러와 성능이슈로 인해 팀원들이 Template을 이용하기 힘들었고,
기존 대회에서 진행했던 방식대로 각 팀원별 수준에 맞게 대회 진행을 하기로 하였다.
NLP 모델학습 시간이 너무 오래 걸려서 팀원 한사람이 다양한 테스트를 하는게 불가능하므로 각 팀원별로 역할을 담당하여 테스트하기로 하였다.
1. 한영번역 - 한아름
2. 모델 찾기 - 위효연
3. 코드 레벨 수정 - 박석
4. 파라미터 튜닝 및 최적화 - 백경탁
제일 먼저 생각난 아이디어는 Baseline code를 이용하여 데이터 전처리 없는 상황에서 성능 좋은 모델을 찾아야 겠다는 생각이 들었다.
HugginFace 에서 요약관련 모델을 검색했으며 BaseLine Code에 없는 두개의 모델을 찾았고,
아래와 같이 세가지 모델을 테스트하여 성능이 제일 좋은 t5모델을 선택하였다.
digit82/kobart-summarization : 41 점대
dudcjs2779/dialogue-summarization-T5 : 42 점대
lcw99/t5-large-korean-text-summary : 43 점대
t5-large-korean-text-summary 선택후에는 데이터를 탐색하였고,
기본 EDA를 통해 오타 정정과 Special Tocken 처리를 하였다.
dialogue와 summary 길이 분포 확인
train_dialog_length = train_df['dialogue'].apply(lambda x:len(x))
train_summary_length = train_df['summary'].apply(lambda x:len(x))
print("대화 길이에 대한 정보")
print(train_dialog_length.describe())
print("=================")
print("요약문 길이에 대한 정보")
print(train_summary_length.describe())val_dialog_length = val_df['dialogue'].apply(lambda x:len(x))
val_summary_length = val_df['summary'].apply(lambda x:len(x))
print("대화 길이에 대한 정보")
print(val_dialog_length.describe())
print("=================")
print("요약문 길이에 대한 정보")
print(val_summary_length.describe())special token 확인하여 추가하기
special_token_list = []
pattern = r"#[a-zA-Z\d\s]*#"
for dialogue in train_df["dialogue"]:
sp_token = re.findall(pattern, dialogue)
special_token_list += sp_token
special_token_list = list(set(special_token_list))
오타 찾기
train_df[train_df['dialogue'].apply(lambda x:x.find('ㅋㅋ')!= -1)].values
train_df[train_df['dialogue'].apply(lambda x:x.find('사람1')!= -1)].values
train_df[train_df['dialogue'].apply(lambda x:x.find('#Person 2#')!= -1)].values
.
.
.
.
.
.
.
.
.
이후에는 파라미터 튜닝을 위해 모든 시간을 쏟아 붓기 시작하였다.
전체적인 내용은 아래와 같은 파라미터 증가 감소에 따른 Rouge점수 변화를 측정하였다.
Learning Rate : [0.000001, 0.00005, 0.00001, 0,00002, 0.00005, 0.0001]
Encoder max length : 512, 660, 700, 850, 1024, 1536
Decoder max length : 100, 125, 150, 200, 400
generation_max_length : 50, 70, 85, 90, 100, 125, 150, 200, 400
weight decay : 0.0, 0.01, 0.001
모든 테스트에 대한 내용은 아래와 같이 엑셀에 정리하였다.




▣ 최종결과
Public Score

Private Score

아쉬운 점
작업 시간과 리소스 부족으로 인해 다양한 모델과 파라미터 튜닝 테스트를 해볼 수 없었던 점이 아쉬웠다.
다른 팀의 EDA내용을 보니 EDA를 좀 더 세밀하게 했어야 했는데... 너무 겉핧기 식으로 했다는 느낌이 든다.
프로젝트 진행시 어려운 점.
전체적으로 NLP 작업시간이 5~6시간은 기본이고 파라미터 조정 및 모델에 따라 12시간 이상 걸리는 작업도 있어서 프로젝트 진행이 쉽지 않았다.
'Upstage AI Lab' 카테고리의 다른 글
| Upstage AI Lab 3기 - IR 프로젝트 테스트 내용 정리 (0) | 2024.10.24 |
|---|---|
| Upstage AI Lab 3기 - Data Centric AI (5) | 2024.10.01 |
| Upstage AI Lab 3기 - Computer Vision & Generation (1) | 2024.08.20 |
| Upstage AI Lab 3기 - Computer Vision [경진대회] Image Classification (0) | 2024.08.13 |
| Upstage AI Lab 3기 - Machine Learning [경진대회] Regression (0) | 2024.07.20 |


