Upstage AI Lab 3기 - Deep Learning & Pytorch
Deep Learning Basic
1. 딥러닝의 기본기 이해 및 구현 능력 습득
2. 실무에서의 딥러닝 적용 능력 향상
3. 현대 딥러닝 아키텍처와 트렌드 이해
목차
1. 기본개념
- 딥러닝 발전 5단계 I : 1단계 ~ 3단계
- 딥러닝 발전 5단계 II : 4단계 ~ 5단계
- 딥러닝 기술 종류들 I : 학습 방식에 의한 구분
- 딥러닝 기술 종류들 II : 데이터 형식, 태스크 종류에 의한 구분
2. 모델학습법
- 딥러닝 개요
- 모델 학습법 I : 다층 퍼셉트론
- 모델 학습법 II : 경사 하강법
- 모델 학습법 III : 역전파 (기초)
- 모델 학습법 III : 역전파 (심화)
- 모델 학습법 IV : 손실 함수
- 모델 학습법 실습
3. 성능 고도화 방법
- 성능 고도화 방법 I : 과적합, 편향과 분산, 지역/전역 최소값, 네트워크 안정화
- 성능 고도화 방법 II : 가중치 초기화, 규제화, 학습률
- 성능 고도화 방법 III : 다양한 최적화 알고리즘
- 성능 고도화 방법 IV : 데이터 증강 및 그 외 방법들
- 성능 고도화 방법 실습
4. 기본모델 구조들
- CNN
- RNN
- From AlexNet to ChatGPT
PyTorch
1. Introduction to PyTorch
1-1 파이토치 소개
1-2 환경 설정
2. Tensor Manipulation
2-1 텐서 조작의 개념
2-2 텐서 조작(1)
2-3 텐서 조작(2)
3. Implement Deep Learning Models
3-1 딥러닝을 위한 파이토치가 어떻게 동작하는가?
3-2 DNN 구현(1)
3-3 DNN 구현(2)
3-4 DNN 구현(3)
3-5 CNN 구현
3-6 RNN 구현
4. Transfer Learning
4-1 전이학습이란?
4-2 timm과 Hugging Face을 통한 전이 학습
5. Trouble Shooting
5-1 모니터링을 위한 TensorBoard와 Wandb
5-2 디버깅
6. PyTorch Lightning with Hydra
6-1 파이토치 라이트닝 소개
6-2 파이토치 코드를 파이토치 라이트닝 코드로 변환하기
6-3 하이드라 소개
6-4 파이토치 라이트닝과 하이드라
Deep Learning Basic
1. 기본개념
1-1 딥러닝 발전 5단계 I : 1단계 ~ 3단계
1-2 딥러닝 발전 5단계 II : 4단계 ~ 5단계

AI구분 : 데이터/학습/태스크 관점으로 구분가능
1-3 딥러닝 기술 종류들 I : 학습 방식에 의한 구분
지도(교사)학습, 비지도학습, 강화학습

지도(교사)학습 :특정 입력에 대한 정답을 알려주는 방식으로 학습
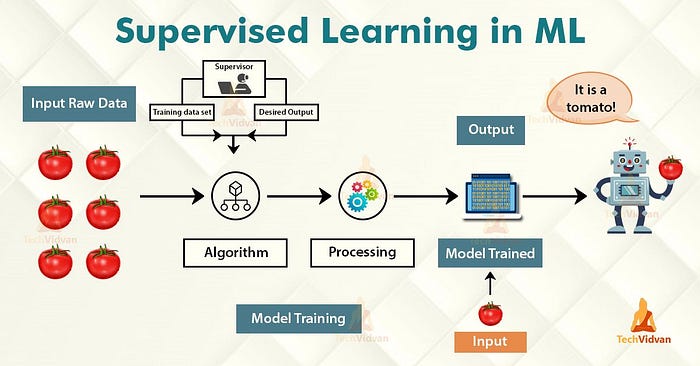
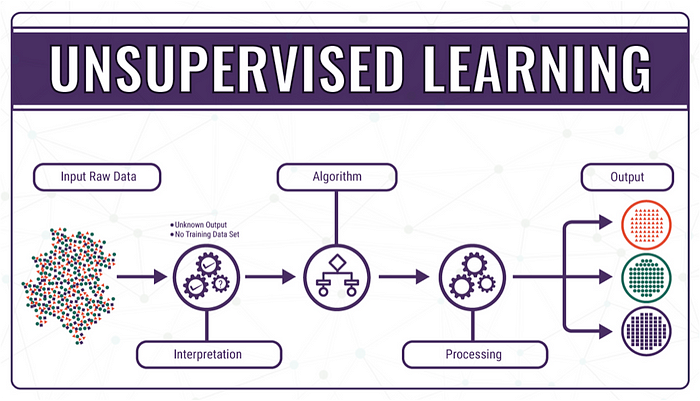
비지도학습:특정 입력에 대한 정답을 알려주지 않고 학습시키는 방법
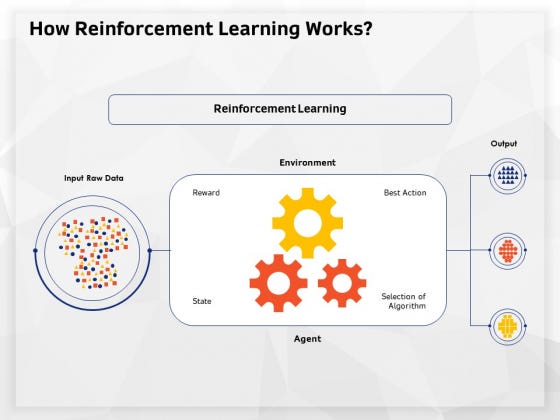
강화학습:주어진 환경에서 더 높은 보상을 위해서 최적의 행동을 취하는 정책을 학습
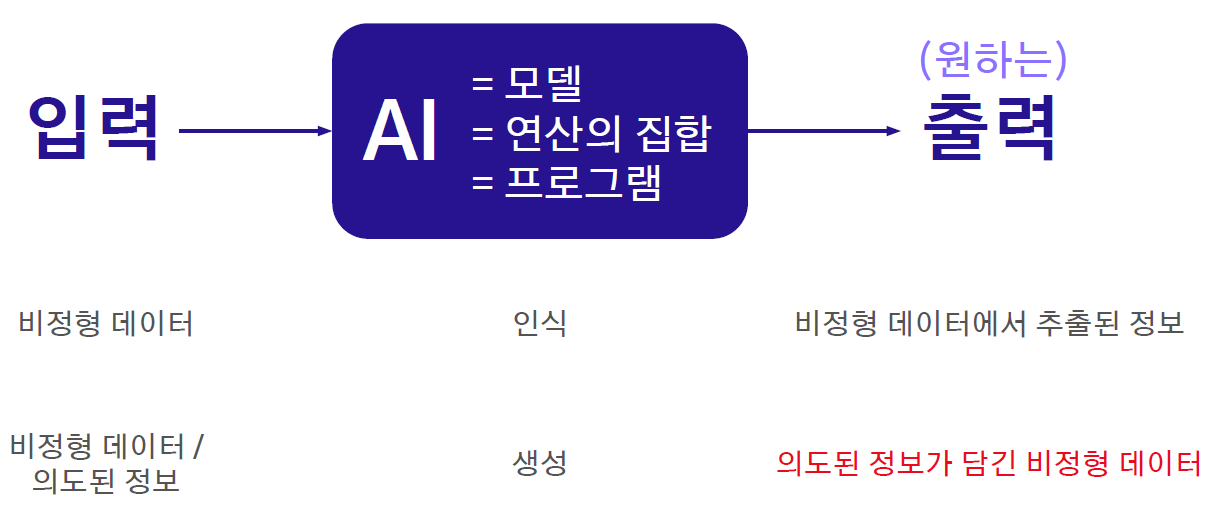
1-4 딥러닝 기술 종류들 II : 데이터 형식, 태스크 종류에 의한 구분
데이터 형식

태스크
2. 모델학습법
2-1 딥러닝 개요
딥러닝을 구성하는 필수적인 요소
● 모델을 학습하기 위해 필요한 데이터 (Data)
… MNIST, Fashion MNIST 등
● 주어진 데이터를 원하는 결과로 변환하는 모델 (Model)
… 다층 퍼셉트론(MLP), 컨볼루션 신경망(CNN), 순환 신경망(RNN) 등
● 모델의 결과에 대한 오차를 수치화하는 손실 함수 (Loss Function)
… 평균절대오차(MAE), 평균제곱오차(MSE), 교차 엔트로피(CE) 등
● 손실 함수의 값이 최소가 되도록 모델의 파라미터를 조정하는 최적화 알고리즘 (Optimization Algorithm)
… 경사 하강법(GD), 확률적 경사 하강법(SGD), 모멘텀(Momentum) 등
● 성능 향상을 위한 기타 알고리즘
… Dropout, Regularization, Normalization 등
1-2 모델 학습법 I : 다층 퍼셉트론
퍼셉트론
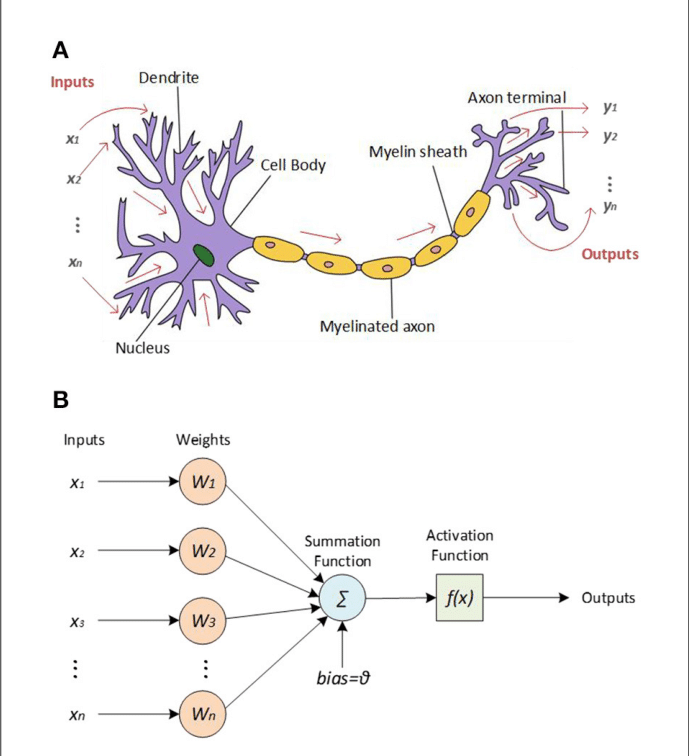
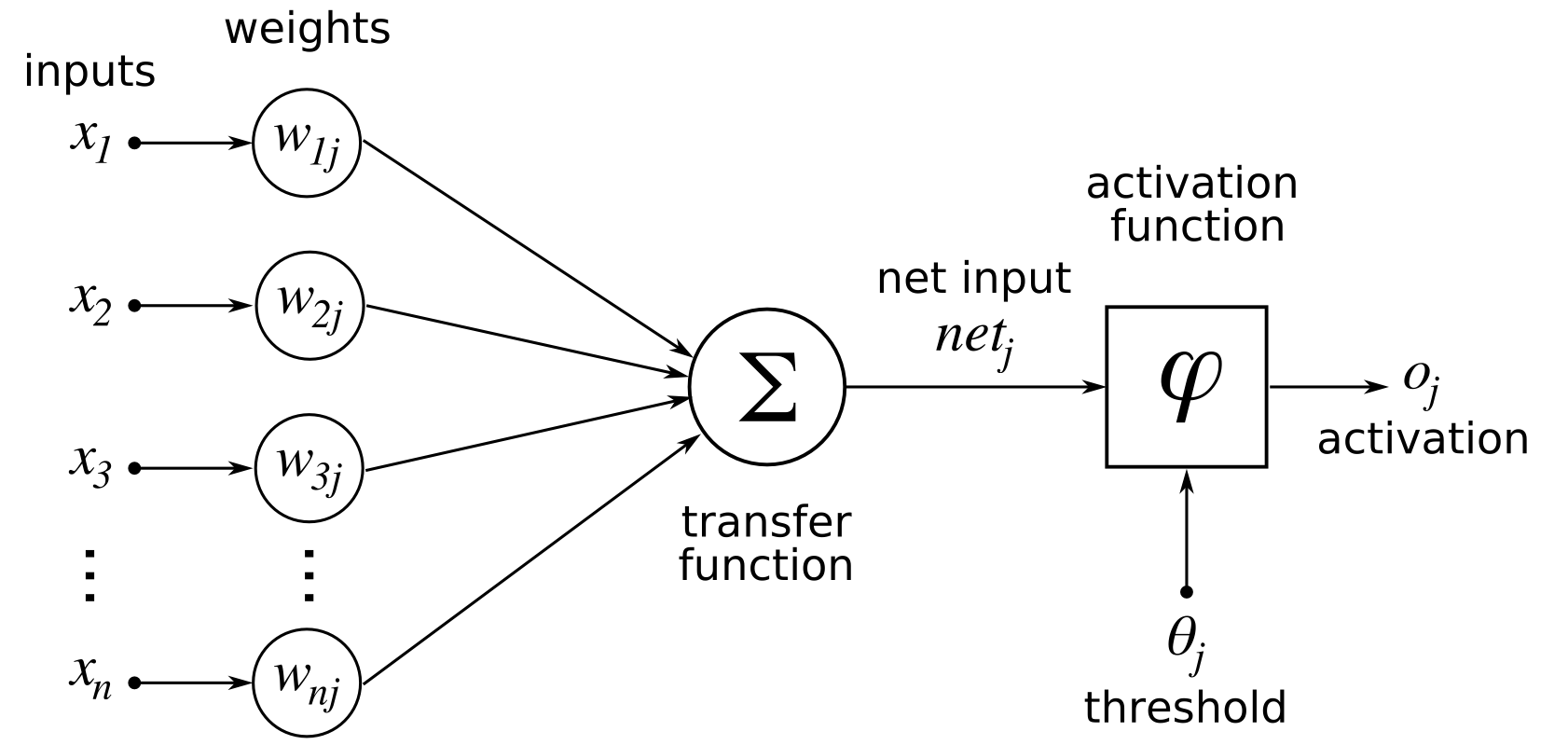

다층 퍼셉트론(MLP)

활성화 함수

1- 3 모델 학습법 II : 경사 하강법
Gradient Descent - 기울기( )가 감소하는 방향으로 를 움직여서 의 최소값을 찾는 알고리즘
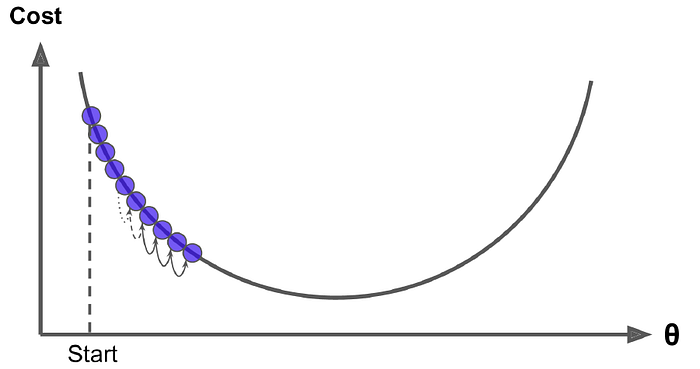
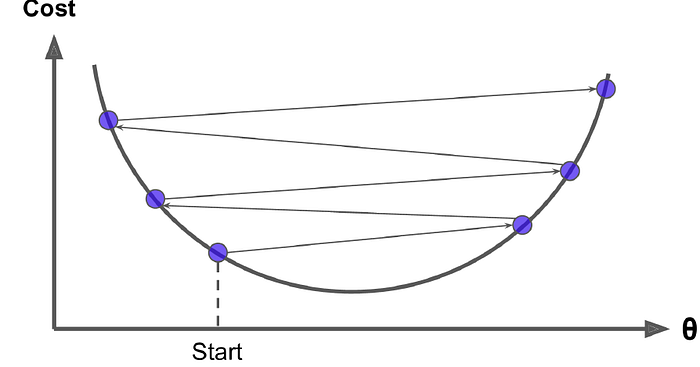

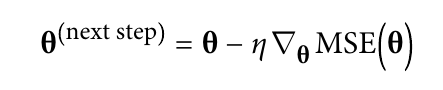
경사 하강법 한계 및 해결방안
1) 파라미터 초기화를 잘한다.
2) 모델 구조를 바꿔서 그래프 모양을 바꾼다.
3) Learning Step을 바꾼다.
확률적 경사 하강법 (Stochastic Gradient Descent, SGD)
: 모든 데이터를 사용해서 구한 경사를 통해 파라미터를 한 번 업데이트 하는 대신,
데이터 한 개 또는 일부를 활용하여 구한 경사로 여러 번 업데이트를 진행
1-4 모델 학습법 III : 역전파 (기초)


1-5 모델 학습법 III : 역전파 (심화)
역전파 기본 방정식

1-6 모델 학습법 IV : 손실 함수
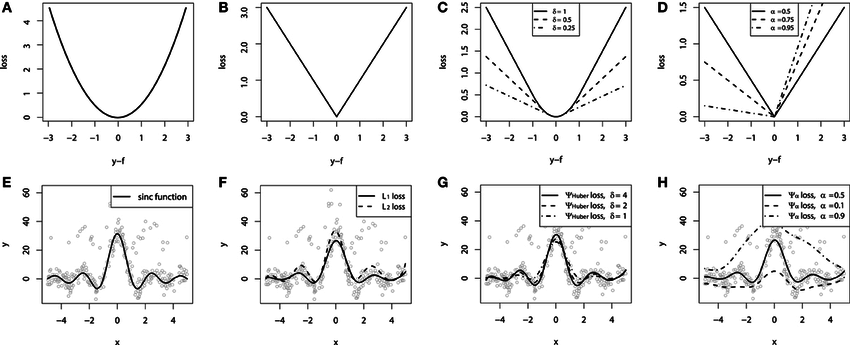
Continuous loss functions:
(A) MSE loss function;
(B) MAE loss function;
(C) Huber loss function;
(D) Quantile loss function.
Demonstration of fitting a smooth GBM to a noisy sinc(x) data:
(E) original sinc(x) function;
(F) smooth GBM fitted with MSE and MAE;
(G) smooth GBM fitted with Huber loss;
(H) smooth GBM fitted with Quantile loss.
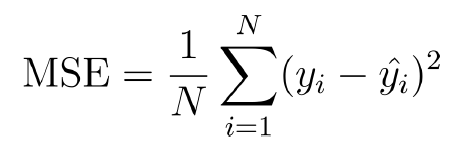
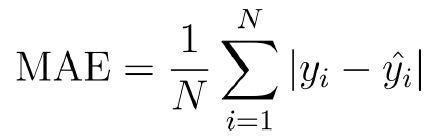
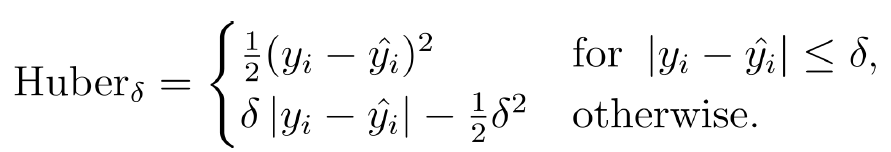
교차 엔트로피 (Cross Entropy, CE)
: 주어진 확률 변수 또는 사건 집합에 대한 두 확률 분포 간의 차이를 측정하는 함수
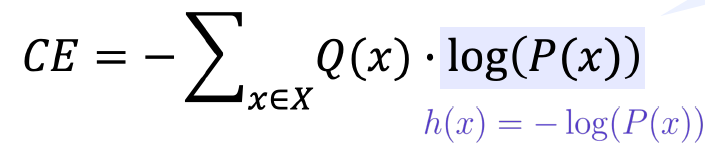
3. 성능 고도화 방법
3-1 성능 고도화 방법 I : 과적합, 편향과 분산, 지역/전역 최소값, 네트워크 안정화
과적합

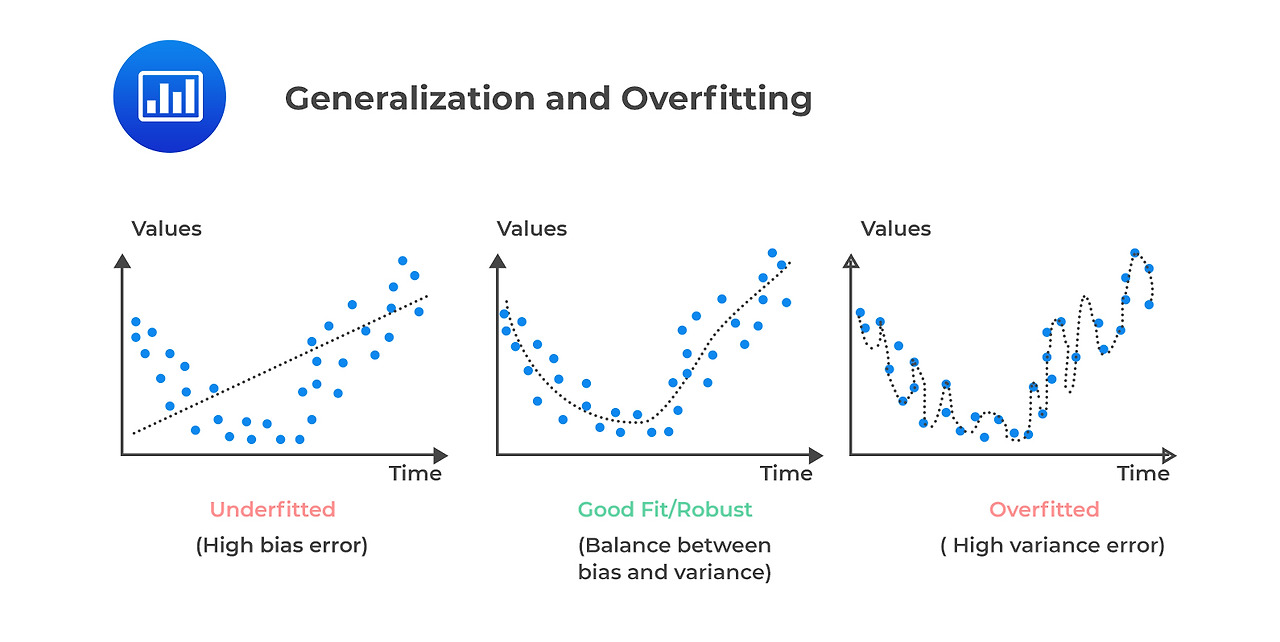
분산과 편향

지역 최소값 vs 전역 최소값
dropout

피쳐스케일
서로 다른 입력 데이터의 값을 일정한 범위로 맞추는 작업이다

정규화

배치 정규화
배치 정규화(Batch Normalization)은 배치(Batch) 단위의 데이터를 기준으로 평균과 분산을 계산하여 활성화 레이어 이후
출력을 정규화하는 방법
레이어 정규화
레이어 정규화(Layer Normalization)은 배치 정규화의 단점을 보완한 방법 중 하나이다. 배치 정규화는 텍스트와 같은 시계열
데이터에서 활용하기 어렵기 때문에 RNN이나 LSTM과 같은 모델에 적용하기 번거롭다. 그렇기 때문에 배치의 크기가 작은 경우
전체 데이터셋에 대한 정보를 반영하기 어렵다. 레이어 정규화는 개별 데이터 샘플 내에서 모든 특징들의 평균과 분산을 계산하여
정규화한다. 배치 정규화와 다르게 배치 사이즈에 무관하게 사용 가능하다.
인스턴스 정규화
인스턴스 정규화(Instance Normalization)은 각 데이터 샘플의 각 채널에서 평균과 분산을 계산하여 정규화한다. 통상적으로
이미지 스타일 변환(Image Style Transfer)와 같은 분야에서 각 데이터의 고유한 정보를 유지하기 위해 사용된다.
그룹 정규화
그룹 정규화(Group Normalization)은 채널을 여러 그룹으로 나눈 후, 각 그룹 내에서의 평균과 분산을 계산하여 정규화하는
방법이다. 레이어 정규화과 비슷하게 배치 정규화의 단점 중 하나인 배치 사이즈를 극복하기 위한 방법 중 하나다. 특히 객체 인식
(Object detection)이나 영역 분할(Segmentation)과 같이 배치 사이즈를 늘리기 어려운 상황에서 활용 가능하다. 이는 앞선
인스턴스 정규화의 확장 버전 중 하나라고 볼 수 있다
3-2 성능 고도화 방법 II : 가중치 초기화, 규제화, 학습률
가중치 초기화
가중치 초기화(Weight Initialization)를 진행하지 않으면 모델의 층이 깊어질수록 활성화 함수 이후 데이터의 분포가
한 쪽으로 쏠릴 수 있다. 이러한 현상은 효율적이고 원활한 모델 학습을 방해한다.

가중치 감쇠란 무엇일까?
가중치 감쇠는 큰 가중치에 대한 패널티를 부과함으로써 모델의 가중치를 작게 유지하려고 한다. 이를 통해 모델의 복잡도를
감소시켜 모델이 훈련 데이터에 과도하게 적합하는 것을 억제하게 된다. 이는 특히 훈련 데이터가 적거나, 훈련 데이터에
노이즈가 많은 경우에 유용하다.
학습 조기 종료
학습 조기 종료(Early stopping)는 모델 학습 시 과적합을 방지해주는 방법 중 하나다.
학습이 진행될수록, 모델의 학습 오차는 계속 해서 줄어들어 과적합이 되고 검증 오차는 어느 순간 증가한다.
이렇게 학습 오차는 줄어들지만 검증 오차가 줄어들지 않고 늘어나는 시점에서 학습을 중지하는 방법이다.
학습 스케쥴러
학습 스케쥴러(Learning rate scheduler)는 딥러닝 훈련 과정에서 사용되는 학습률을 동적으로 조절하는 역할을 한다.
적절한 학습률 스케줄링은 학습 속도를 빠르게 하고, 지역 최소값을 벗어나게 하며, 일반적으로 더 나은 성능의 모델을 얻게
도와준다.
3-3 성능 고도화 방법 III : 다양한 최적화 알고리즘
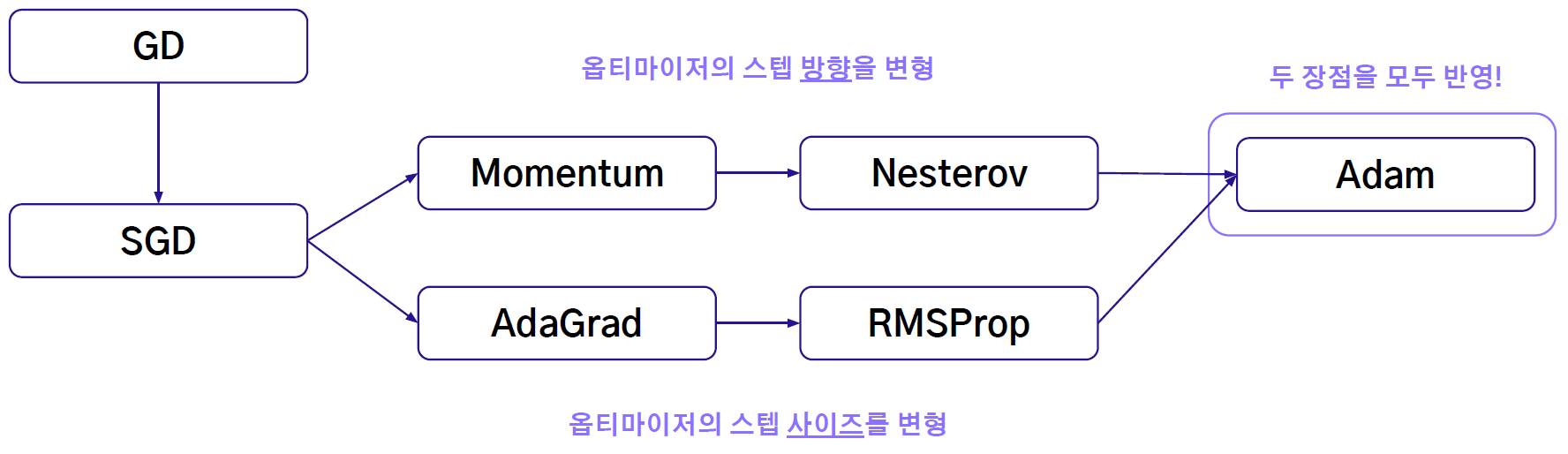
Gradient Descent (GD)

3-4 성능 고도화 방법 IV : 데이터 증강 및 그 외 방법들
데이터 증강 기법
주의 해야할 점
함부로 데이터를 변형하여 증폭시키면 안 된다. 해당 데이터의 도메인(Domain)을 잘 고려해서 처리해야 한다.
그렇기 때문에 데이터 증강 기법을 적용할 때 문맥이나 의미를 왜곡하지 않도록 주의해야 한다.
텍스트 데이터 증강
동의어 대체(Synonym Replacement, SR)
무작위 삽입(Random Insertion, RI)
무작위 교체(Random Swap, RS)
무작위 삭제(Random Deletion, RD)
역번역(Back Translation)을 이용한 방법
사전학습된 언어모델(Pretrained LM)을 이용한 방법
전이 학습
딥러닝에서도 어떤 데이터에 대해 모델을 처음부터 학습시킬 필요가 없다. 전이 학습(Transfer Learning)은 이미 다른 문제에
대해 학습된 모델의 지식을 새로운 작업에 활용하는 방법이다. 다시 말해, 하나의 문제를 해결하기 위해 학습된 지식을 다른
문제에 '전이(Transfer)'시키는 방법이다
4. 기본모델 구조들
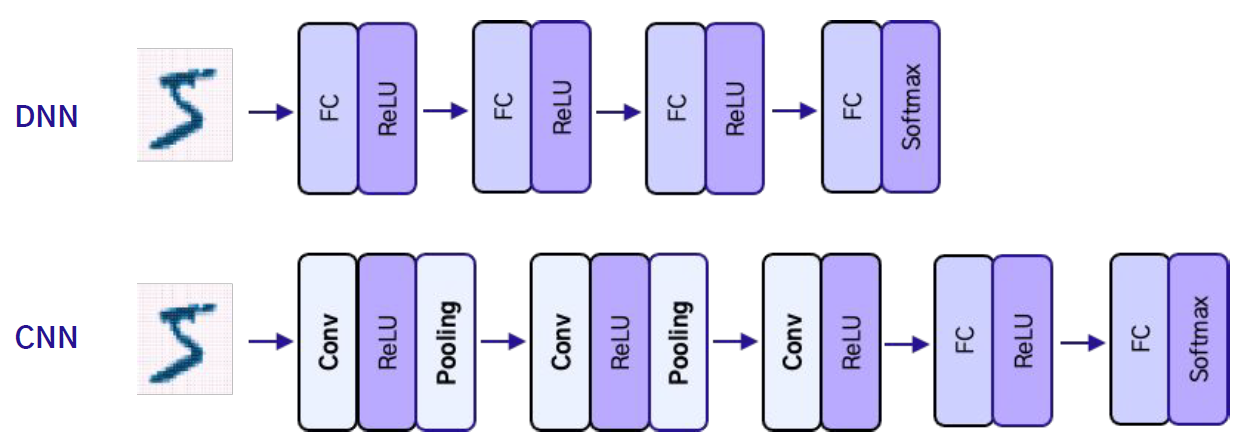
4-1 CNN
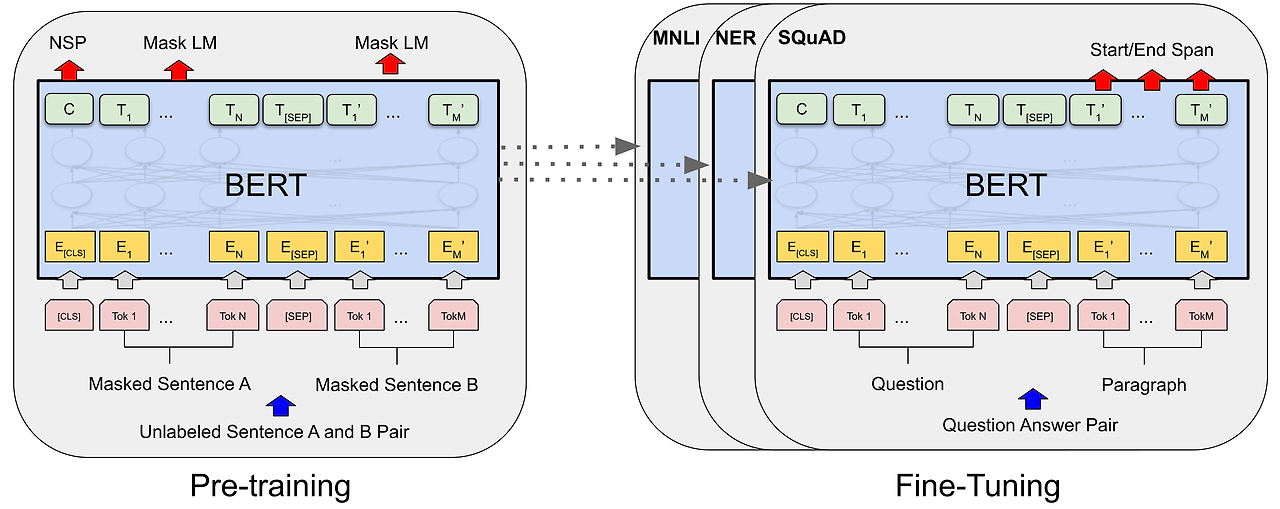
합성곱 연산
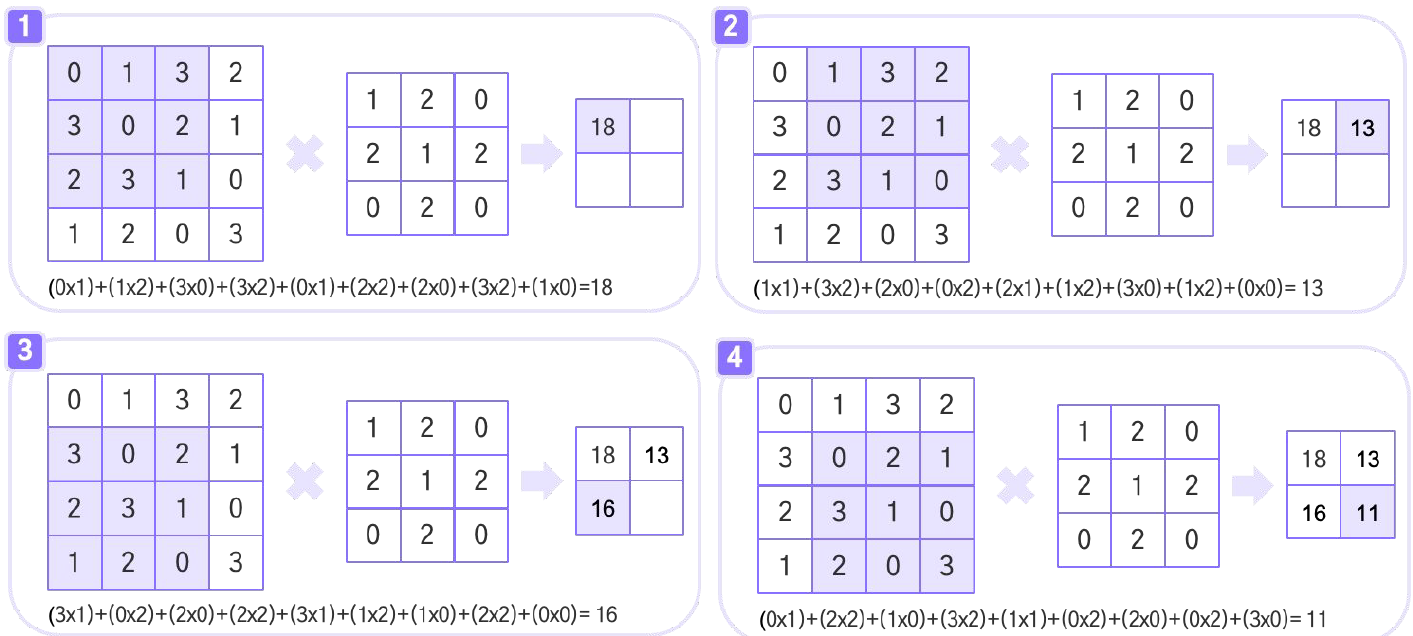
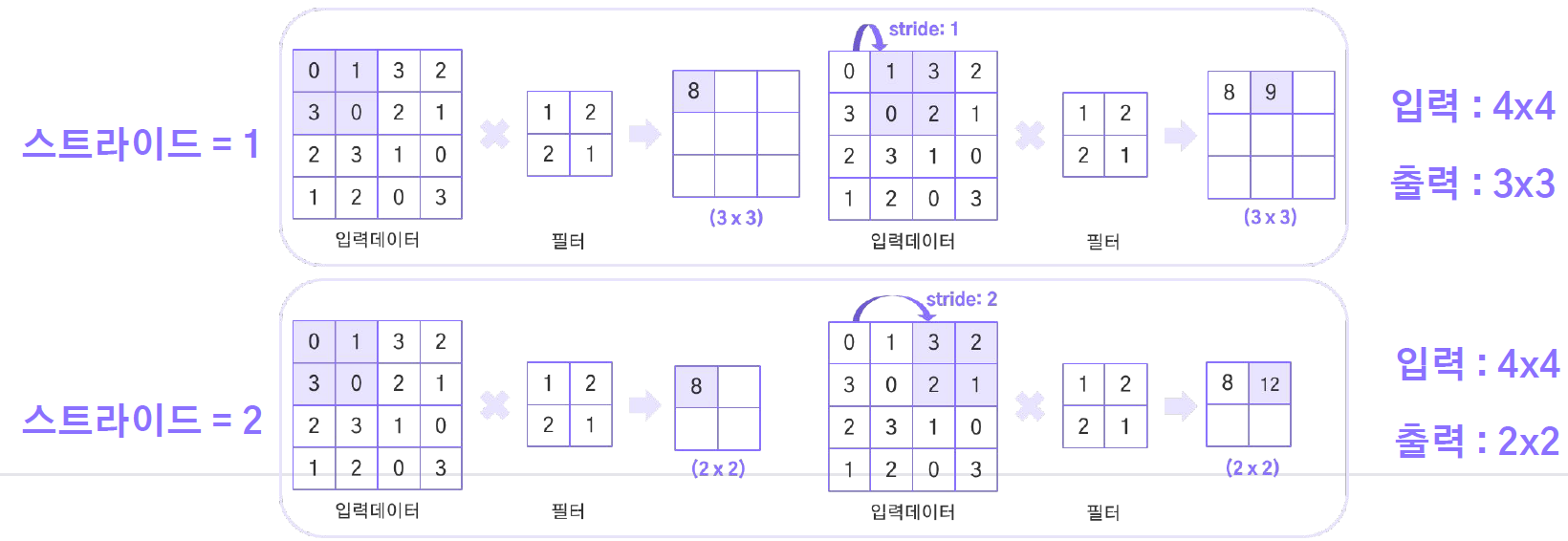
스트라이드(Stride)
패딩

CNN 연산처리

4-2 RNN
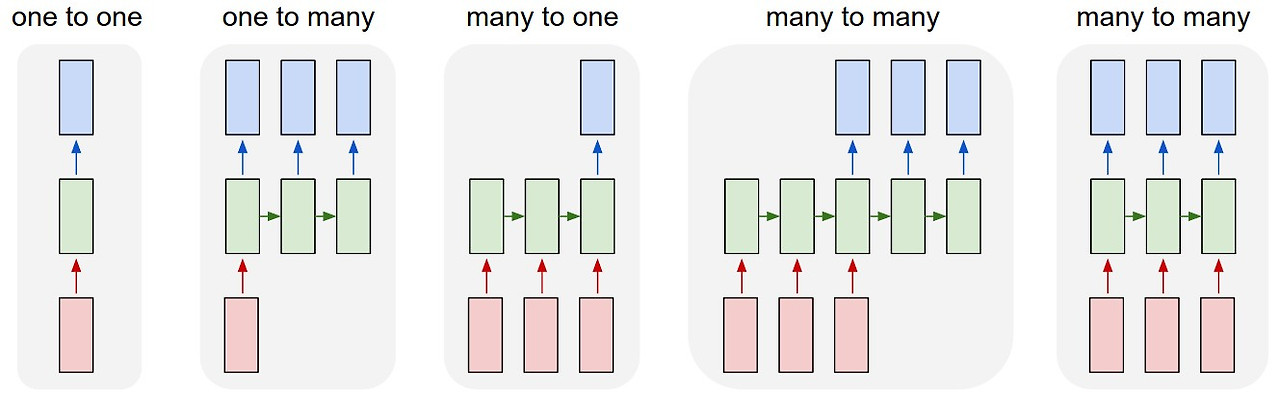
기존의 인공신경망(DNN)이나 합성곱 신경망(CNN)은 주로 고정된 크기(Fixed size)의 입력과 출력을 처리하도록 설계
순환 신경망(Recurrent Neural Network, RNN)

순환 신경망의 핵심은 이전 시점의 정보를 현재 시점의 입력과 함께 처리하는 순환 구조
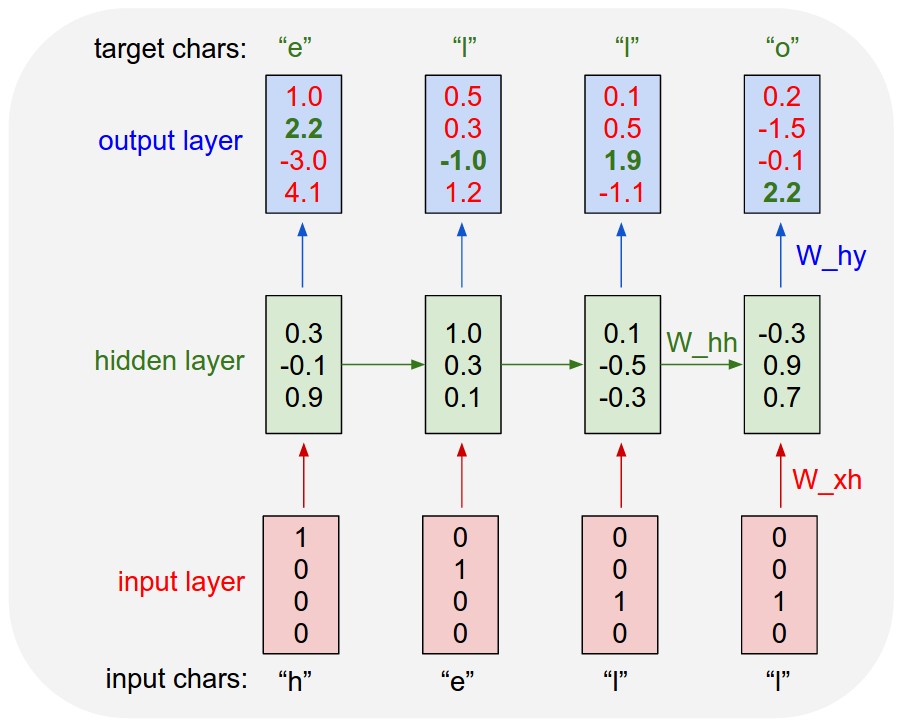
순환 신경망 구조
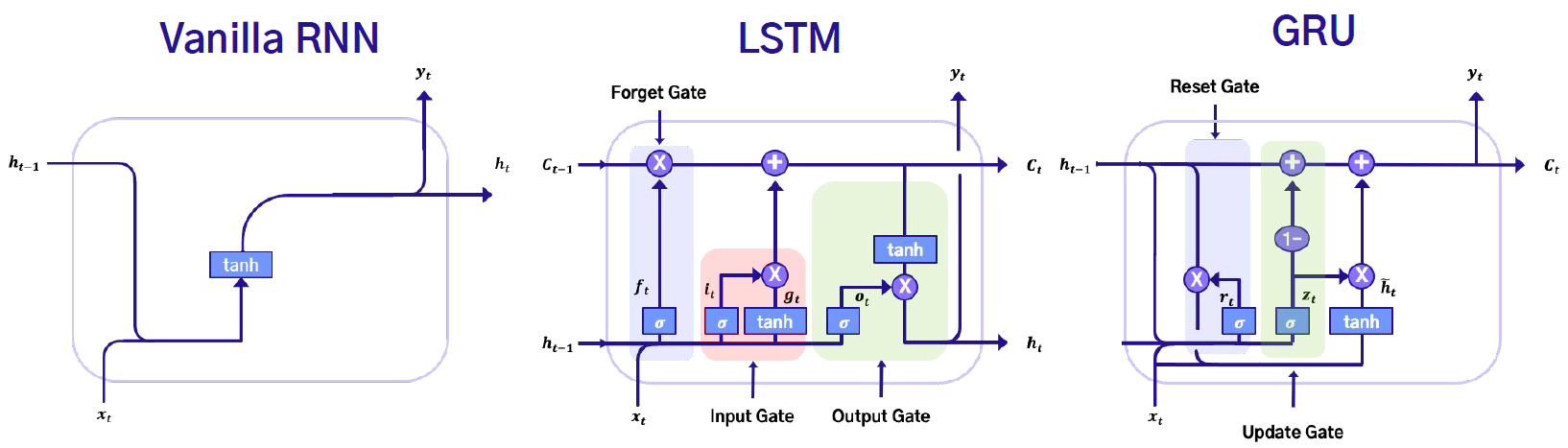
RNN , LSTM (Long Short-Term Memory), GRU (Gated Recurrent Unit)
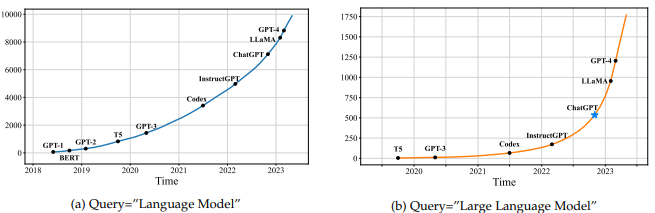
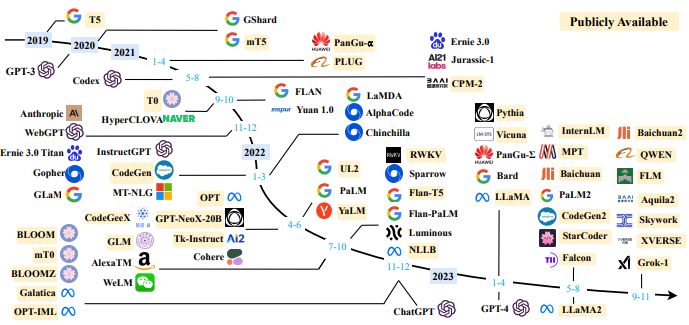
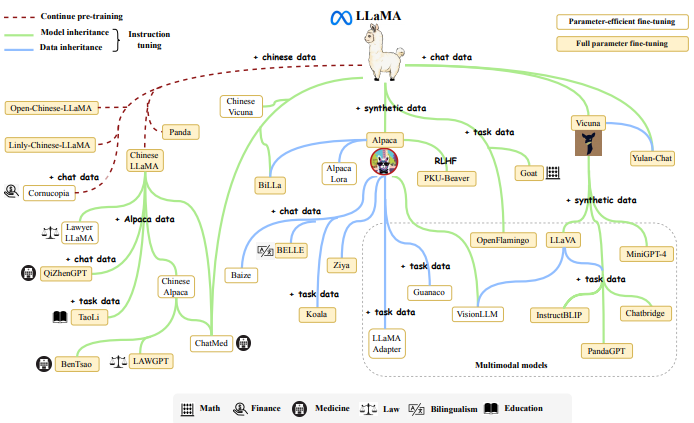
4-3 From AlexNet to ChatGPT
https://arxiv.org/pdf/2303.18223


PyTorch
1. Introduction to PyTorch
1-1 파이토치 소개
딥러닝 프레임워크
1. 모든 neural network의 layer를 직접 구현
→ 모델을 구성하는데 필요한 모든 구성 요소를 제공
2. loss function 구현
→ 다양한 loss function 제공
3. 모든 layer의 weight, bias에 대해 gradient를 계산
→ 자동 미분
4. 최적화 알고리즘 구현
→ 다양한 optimizer 제공
TensorFlow(Google)
PyTorch(Meta)
JAX(Google)
MXNet(Apache)
1-2 환경 설정
Anaconda 설치
PyTorch 설치
2. Tensor Manipulation
2-1 텐서 조작의 개념
텐서 = 데이터 배열
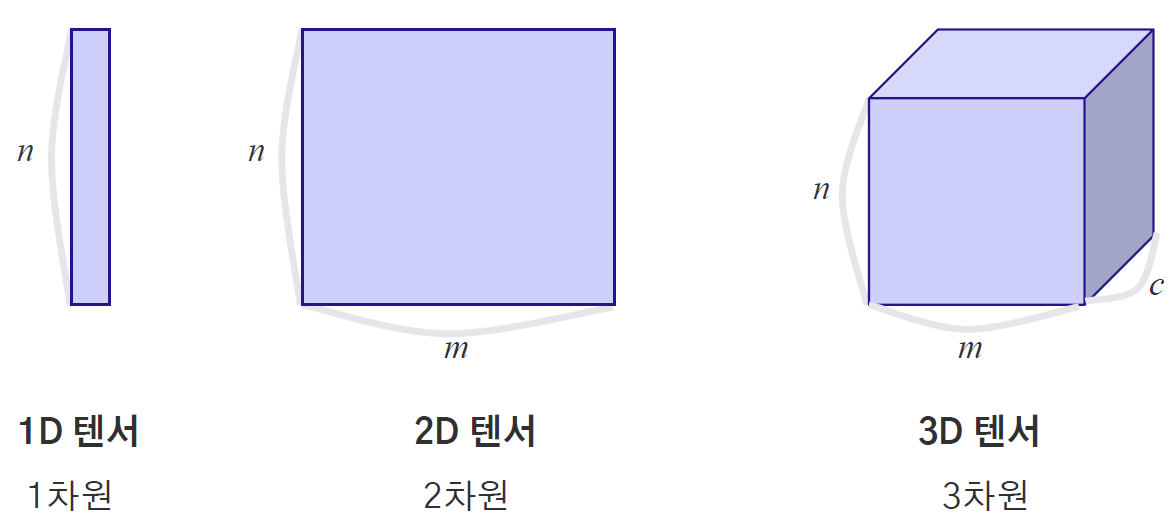
텐서 연산
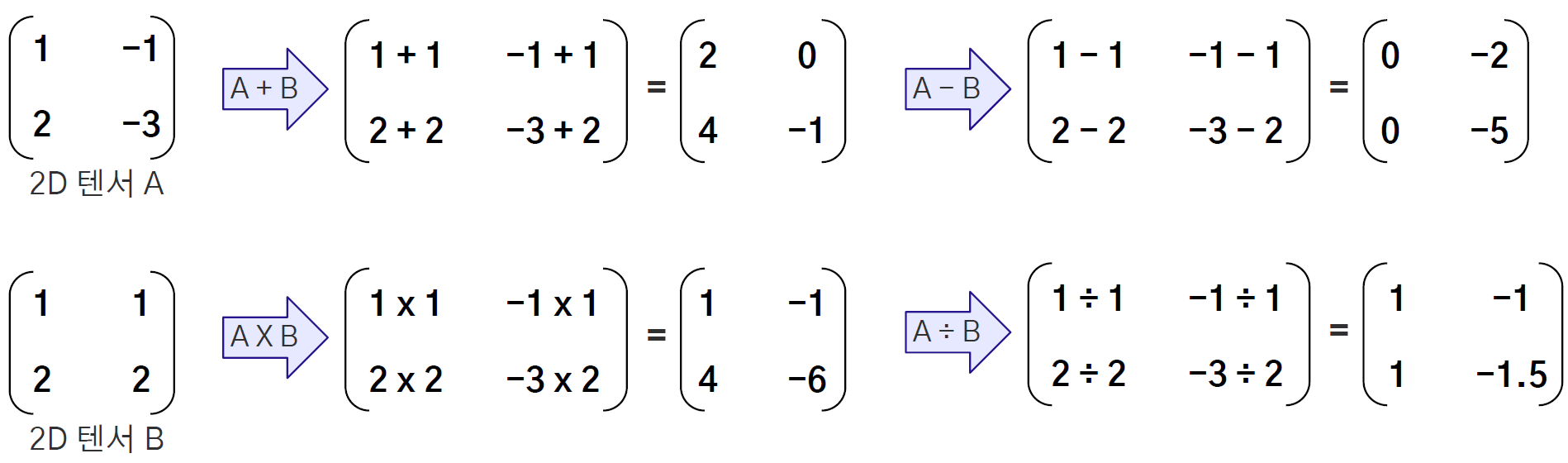

행렬곱셉
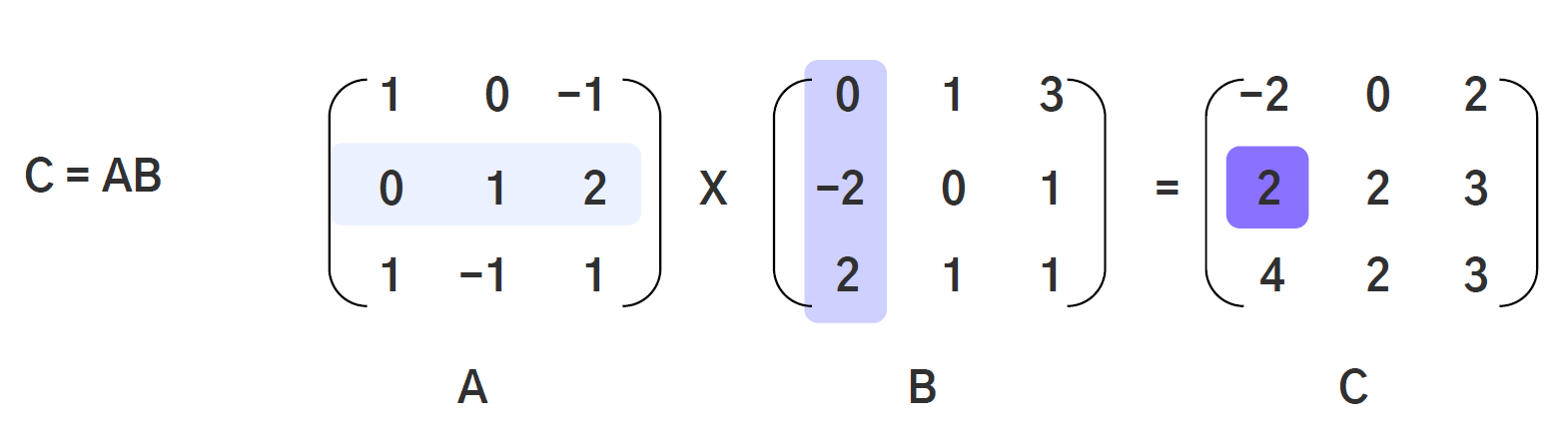
브로드 캐스팅

Sparse CSR/CSC Tensor



2-2 텐서 조작(1)
* 1. 텐서 이해하기
* 1-1. 텐서를 생성하고 텐서로 변환하는 방법을 이해 및 실습
* 1-2. 텐서에서의 indexing 이해 및 실습
* 2. 텐서의 모양 바꾸기
* 2-1. 텐서의 shape 을 바꾸는 여러가지 함수 이해 및 실습
* 2-2. 텐서의 차원을 추가하거나 변경하는 방법에 대한 이해 및 실습
* 2-3. 역할이 비슷한 함수들의 차이 이해 및 실습
* 3. 텐서 합치기와 나누기
* 3-1. 여러 텐서를 합치는 방법에 대한 이해 및 실습
* 3-2. 하나의 텐서를 여러개로 나누는 방법에 대한 이해 및 실습
# 0부터 1 사이의 값을 랜덤하게 NxM 텐서로 반환
torch.rand(2, 3) # torch.rand(NxM) NxM은 텐서의 크기를 말합니다.
# 가우시안 분포에서 렌덤하게 값을 추출 후, NxM 텐서로 반환
torch.randn(2, 3) # torch.randn(NxM) NxM은 텐서의 크기를 말합니다.
# 범위 내의 정수를 N x M 텐서로 반환
torch.randint(1, 10, (5, 5)) # 생성 가능한 최솟값 : 1, 최댓값 : 9, (5x5) Tensor 크기
# torch.zeros(*size) 여기서 size 는 ","로 구분하며 차원을 여러개로 늘릴 수 있음.
torch.zeros(3, 3)
# torch.ones(*size) 여기서 size 는 ","로 구분하며 채널을 여러개로 늘릴 수 있음.
torch.ones(2, 2, 2)
# torch.full((size),value) => 괄호로 텐서의 크기 (2,3) 를 입력하고, 지정한 값 value (5) 로 모든 요소가 설정.
torch.full((2, 3), 5)
# torch.eye(n) (nxn) 크기를 가지는 단위 행렬 반환, 단위행렬 특성 상 정사각행렬 (square matrix)만 가능
torch.eye(3)
# list, tuple, numpy array를 텐서로 바꾸기
ls = [[1, 2, 3, 4, 5],[6, 7, 8, 9, 10]] # sample list 생성
tup = tuple([1, 2, 3]) # sample tuple 생성
arr = np.array([[[1, 2, 3],[4, 5, 6]],[[7, 8, 9],[10, 11, 12]]]) # sample numpy array 생성
print(torch.tensor(ls))
print('\n')
print(torch.tensor(tup))
print('\n')
print(torch.tensor(arr))
as_tensor: 변환 전 데이터와의 메모리 공유(memory sharing)를 사용하므로, 변환 전 데이터 변경 시 변환되어 있는 텐서에도 반영됨
Tensor : float32 type으로 텐서 변환(T 대문자)
* 인덱싱
# 3차원 텐서에서 Indexing 하기
tmp_3dim = torch.randn(4, 3, 2) # 4채널, 3행, 2열
print("Shape : ", tmp_3dim.shape)
print(tmp_3dim)
print('-------'*8)
print(tmp_3dim[:,:,0].shape)
print(tmp_3dim[:,:,0]) # 전체 채널과 전체 행에서 0번째 열만 추출
print('\n') # 줄 띄움
print(tmp_3dim[0,:,1].shape)
print(tmp_3dim[0,:,1]) # 0번째 채널의 전체 행에서 1번째 열만 추출
# index_select
tmp_2dim = torch.tensor([[i for i in range(10)],[i for i in range(10, 20)]])
print(tmp_2dim)
print('\n')
my_index = torch.tensor([0, 2]) # 선택하고자 하는 index 는 텐서 형태이어야 함.
torch.index_select(tmp_2dim, dim=1, index=my_index) # 열을 기준으로 0열과 2열을 추출
텐서 shape 변경
# 모양 변경
a = torch.randn(2, 3, 5) # (2,3,5) 크기를 가지는 텐서 생성
print(a)
print("Shape : ", a.size()) # 텐서 모양 반환
print('\n')
reshape_a = a.reshape(5, 6) # 3차원 텐서를 2차원 텐서로 크기 변경 (2,3,5) -> (5,6)
print(reshape_a)
print("Shape : ", reshape_a.size()) # 변경한 텐서 모양 반환
# -1 로 모양 자동 설정
# (2,3,5) 크기를 가지는 Tensor를 (3,n)의 모양으로 변경, "-1" 로 크기 자동 계산
reshape_auto_a = a.reshape(3, -1)
print(reshape_auto_a.size()) # 2x3x5 = 3 x n 의 방정식을 푸는 문제로 n 이 자동설정
=> torch.Size([3, 10])
transpose : 텐서 차원 전치
tensor_a.transpose(1, 2) # 행과 열을 서로 전치, 서로 전치할 차원 2개를 지정
print(tensor_a)
print("Shape : ", tensor_a.size())
print('\n')
permute_a = tensor_a.permute(0, 2, 1) # (3,2,5)의 모양을 (3,5,2)의 모양으로 변경
print(permute_a)
print("Shape : ", permute_a.size())
unsqueeze : 텐서 특정 차원에 크기가 1인 차원 추가
tensor_a = torch.tensor([i for i in range(10)]).reshape(5, 2) # 0부터 9까지의 숫자들을 (5,2) 크기로 변경
print(tensor_a)
print('Shape : ', tensor_a.size())
print('\n')
unsqu_a = tensor_a.unsqueeze(0) # 0번째 차원 하나 추가 (5,2) => (1,5,2)
print(unsqu_a)
print('Shape : ', unsqu_a.size())
squeeze : 텐서 차원의 크기가 1인 차원 제거
print(unsqu_a)
print("Shape : ", unsqu_a.size())
print('\n')
squ = unsqu_a.squeeze() # 차원이 1인 차원을 제거
print(squ)
print("Shape : ", squ.size())
x = torch.zeros(2, 1, 2, 1, 2) # 모든 원소가 0인 (2,1,2,1,2) 크기를 가지는 텐서
print("Shape (original) : ", x.size()) # 원래 텐서 크기
print('\n')
print("Shape (squeeze()) :", x.squeeze().size()) # 차원이 1인 차원이 여러개일 때, 모든 차원이 1인 차원 제거
print('\n')
print("Shape (squeeze(0)) :", x.squeeze(0).size()) # 0번째 차원은 차원의 크기가 1이 아니므로, 변화 없음
print('\n')
print("Shape (squeeze(1)) :", x.squeeze(1).size()) # 1번째 차원은 차원의 크기가 1이므로 제거
print('\n')
print("Shape (squeeze(0,1,3)) :", x.squeeze((0, 1, 3)).size())
# 여러 차원 제거 가능 (0번째 차원은 차원의 크기가 1이 아니기 때문에 무시)
Shape (original) : torch.Size([2, 1, 2, 1, 2])
Shape (squeeze()) : torch.Size([2, 2, 2])
Shape (squeeze(0)) : torch.Size([2, 1, 2, 1, 2])
Shape (squeeze(1)) : torch.Size([2, 2, 1, 2])
Shape (squeeze(0,1,3)) : torch.Size([2, 2, 2])
flatten : 다차원 텐서를 1차원 텐서로 변경
t = torch.tensor([i for i in range(20)]).reshape(2, 5, 2) # 0부터 19까지의 숫자를 4행 5열 Tensor로 구성
print(t)
print("Shape : ", t.size())
print('\n')
flat_tensor = t.flatten() # (2, 5, 2) 의 Tensor를 (20,)로 모양 변경, 1차원으로 변경
print(flat_tensor)
print("Shape : ", flat_tensor.size())
ravel : 다차원 텐서를 1차원 텐서로 변경
t = torch.tensor([i for i in range(20)]).reshape(2, 5, 2) # 0부터 19까지의 숫자를 (2, 5, 2) 크기 Tensor로 구성
print(t)
print("Shape : ", t.size())
print('\n')
ravel_tensor = t.ravel() # flatten 과 동일하게 (2,5,2) 의 텐서를 (20,)로 모양 변경, 1차원으로 변경
print(ravel_tensor)
print("Shape : ", ravel_tensor.size())
2-3 텐서 조작(2)
* add : 텐서 간의 덧셈을 수행합니다. (+)
* torch.add(a, b)
* a.add(b)
* a + b
* sub : 텐서 간의 뺄셈을 수행합니다. (-)
* torch.sub(a, b)
* a.sub(b)
* a - b
* mul : 텐서 간의 곱셈을 수행합니다. (*)
* torch.mul(a, b)
* a.mul(b)
* a * b
* div : 텐서 간의 나눗셈을 수행합니다. (/)
* torch.div(a, b)
* a.div(b)
* a / b
* sum : 텐서의 원소들의 합을 반환
* mean : 텐서의 원소들의 평균을 반환
* max : 텐서의 원소들의 가장 큰 값을 반환
* min : 텐서의 원소들의 가장 작은 값을 반환
* argmax : 텐서의 원소들의 가장 큰 값의 **위치** 반환
* argmin : 텐서의 원소들의 가장 작은 값의 **위치** 반환
* dot : **벡터**의 내적 (inner product) 반환
* torch.dot(a,b)
* a.dot(b)
* matmul : 두 텐서 간의 행렬곱 반환 ***※ 원소 곱과 다름 주의❗***
* torch.matmul(a,b)
* a.matmul(b)
tensor_a = torch.eye(3)
print("Tensor A : \n",tensor_a)
print('\n')
tensor_b = torch.tensor([1, 2, 3])
print("Tensor B : \n", tensor_b)
print('\n')
print('A + B : \n', tensor_a + tensor_b) # broadcasting을 통해 (3,) 인 B가 (3,3)으로 변환되어 계산 (행의 확장)
* sparse_coo_tensor : COO 형식의 sparse tensor 를 생성하는 함수
* indices : 0 이 아닌 값을 가진 행,열의 위치
* values : 0 이 아닌 값
* nnz : 0 이 아닌 값의 개수
* to_sparse_csr : Dense tensor를 CSR 형식의 Sparse tensor로 변환하는 함수
* crow_indices : 0 이 아닌 값을 가진 행의 위치 (첫번째는 무조건 0)
* col_indices : 0 이 아닌 값을 가진 열의 위치
* values : 0 이 아닌 값
* nnz : 0 이 아닌 값의 개수
* to_sparse_csc : Dense tensor를 CSC 형식의 Sparse tensor로 변환하는 함수
* ccol_indices : 0 이 아닌 값의 열 위치 (첫번째 원소는 무조건 0)
* row_indices : 0 이 아닌 값의 행 위치
* values : 0 이 아닌 값들
* nnz : 0 이 아닌 값의 개수
* sparse_csr_tensor : CSR 형식의 Sparse tensor 를 생성하는 함수
* sparse_csc_tensor : CSC 형식의 Sparse tensor 를 생성하는 함수
* 아주 큰 크기의 matrix 를 구성할 때, 일반적인 dense tensor 는 메모리 아웃 현상이 발생하지만,
sparse tensor 는 메모리 아웃현상이 발생하지 않습니다.
* to_dense() : sparse tensor 를 dense tensor 로 만드는 함수
# Sparse 와 Sparse Tensor 간의 연산 (2차원)
a = torch.tensor([[0, 1], [0, 2]], dtype=torch.float)
b = torch.tensor([[1, 0],[0, 0]], dtype=torch.float)
sparse_a = a.to_sparse()
sparse_b = b.to_sparse()
print('덧셈')
print(torch.add(a, b).to_dense() == torch.add(sparse_a, sparse_b).to_dense())
print('\n')
print('곱셈')
print(torch.mul(a, b).to_dense() == torch.mul(sparse_a, sparse_b).to_dense())
print('\n')
print('행렬곱')
print(torch.matmul(a, b).to_dense() == torch.matmul(sparse_a, sparse_b).to_dense())
3. Implement Deep Learning Models
3-1 딥러닝을 위한 파이토치가 어떻게 동작하는가?
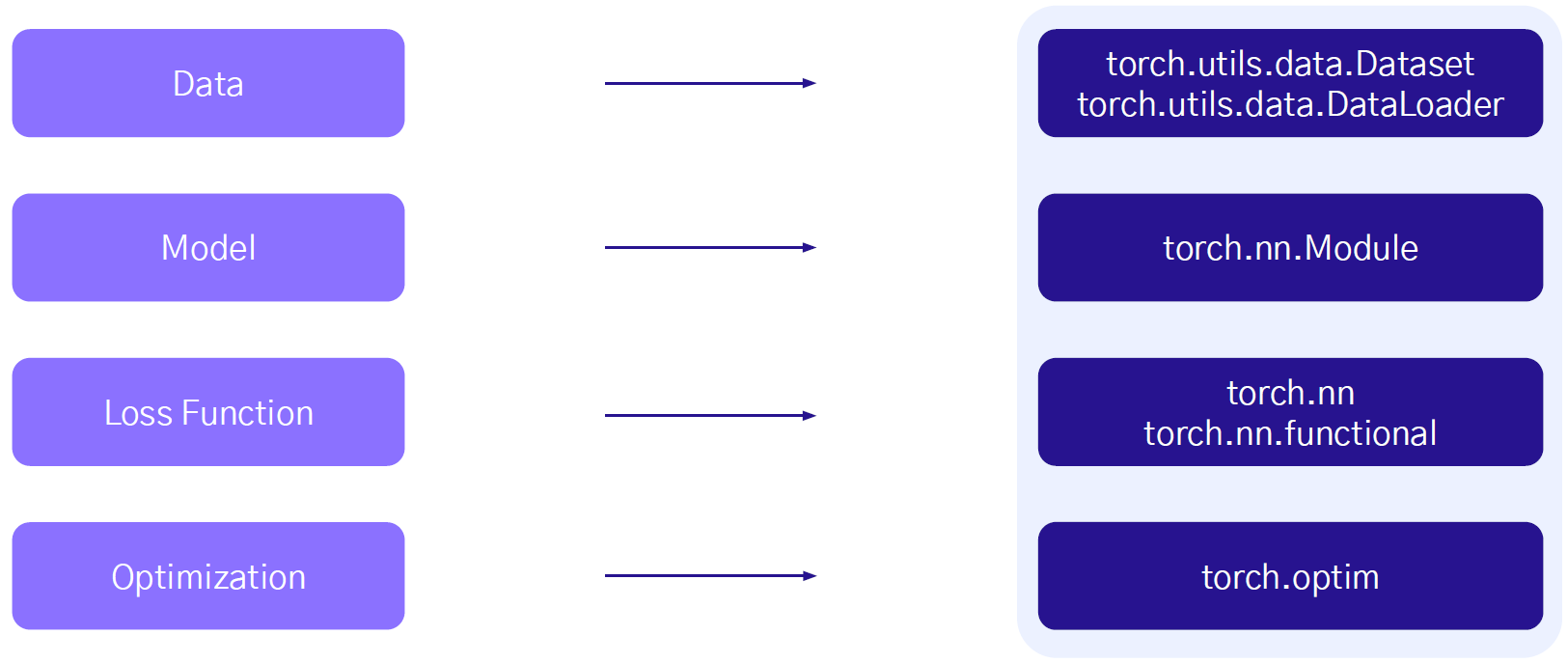
딥러닝 학습단계
Data => Model => Output => Loss => Optimization

3-2 DNN 구현(1,2,3)
import numpy as np # 기본적인 연산을 위한 라이브러리
import matplotlib.pyplot as plt # 그림이나 그래프를 그리기 위한 라이브러리
from tqdm.notebook import tqdm # 상태 바를 나타내기 위한 라이브러리
import pandas as pd # 데이터프레임을 조작하기 위한 라이브러리
import torch # PyTorch 라이브러리
import torch.nn as nn # 모델 구성을 위한 라이브러리
import torch.optim as optim # optimizer 설정을 위한 라이브러리
from torch.utils.data import Dataset, DataLoader # 데이터셋 설정을 위한 라이브러리
from torchtext.data import get_tokenizer # torch에서 tokenizer를 얻기 위한 라이브러리
import torchtext # torch에서 text를 더 잘 처리하기 위한 라이브러리
from sklearn.metrics import accuracy_score # 성능지표 측정
from sklearn.model_selection import train_test_split # train-validation-test set 나누는 라이브러리
import re # text 전처리를 위한 라이브러리
# seed 고정
import random
import torch.backends.cudnn as cudnn
def random_seed(seed_num):
torch.manual_seed(seed_num)
torch.cuda.manual_seed(seed_num)
torch.cuda.manual_seed_all(seed_num)
np.random.seed(seed_num)
cudnn.benchmark = False
cudnn.deterministic = True
random.seed(seed_num)
random_seed(42)
data_csv = pd.read_csv('medium_data.csv')
data_csv.head()
# 각각의 title만 추출합니다.
data = data_csv['title'].values
def cleaning_text(text):
cleaned_text = re.sub( r"[^a-zA-Z0-9.,@#!\s']+", "", text) # 특수문자 를 모두 지우는 작업을 수행합니다.
cleaned_text = cleaned_text.replace(u'\xa0',u' ') # No-break space를 unicode 빈칸으로 변환
cleaned_text = cleaned_text.replace('\u200a',' ') # unicode 빈칸을 빈칸으로 변환
return cleaned_text
cleaned_data = list(map(cleaning_text, data)) # 모든 특수문자와 공백을 지움
print('Before preprocessing')
print(data[:5])
print('After preprocessing')
print(cleaned_data[:5])
# 토크나이저를 통해 단어 단위의 토큰을 생성합니다.
tokenizer = get_tokenizer("basic_english")
tokens = tokenizer(cleaned_data[0])
print("Original text : ", cleaned_data[0])
print("Token: ", tokens)
# 단어 사전을 생성한 후, 시작과 끝 표시를 해줍니다.
vocab = torchtext.vocab.build_vocab_from_iterator(map(tokenizer, cleaned_data)) # 단어 사전을 생성합니다.
vocab.insert_token('<pad>', 0)
id2token = vocab.get_itos() # id to string
id2token[:10]
token2id = vocab.get_stoi() # string to id
token2id = dict(sorted(token2id.items(), key=lambda item: item[1]))
for idx, (k,v) in enumerate(token2id.items()):
print(k,v)
if idx == 5:
break
vocab.lookup_indices(tokenizer(cleaned_data[0])) # 문장을 토큰화 후 id로 변환합니다.
seq = []
for i in cleaned_data:
token_id = vocab.lookup_indices(tokenizer(i))
for j in range(1, len(token_id)):
sequence = token_id[:j+1]
seq.append(sequence)
max_len = max(len(sublist) for sublist in seq) # seq에 저장된 최대 토큰 길이 찾기
def pre_zeropadding(seq, max_len): # max_len 길이에 맞춰서 0 으로 padding 처리 (앞부분에 padding 처리)
return np.array([i[:max_len] if len(i) >= max_len else [0] * (max_len - len(i)) + i for i in seq])
zero_padding_data = pre_zeropadding(seq, max_len)
zero_padding_data[0]
input_x = zero_padding_data[:,:-1]
label = zero_padding_data[:,-1]
class CustomDataset(Dataset):
def __init__(self, data, vocab, tokenizer, max_len):
self.data = data
self.vocab = vocab
self.max_len = max_len
self.tokenizer = tokenizer
seq = self.make_sequence(self.data, self.vocab, self.tokenizer) # next word prediction을 하기 위한 형태로 변환
self.seq = self.pre_zeropadding(seq, self.max_len) # zero padding으로 채워줌
self.X = torch.tensor(self.seq[:,:-1])
self.label = torch.tensor(self.seq[:,-1])
def make_sequence(self, data, vocab, tokenizer):
seq = []
for i in data:
token_id = vocab.lookup_indices(tokenizer(i))
for j in range(1, len(token_id)):
sequence = token_id[:j+1]
seq.append(sequence)
return seq
def pre_zeropadding(self, seq, max_len): # max_len 길이에 맞춰서 0 으로 padding 처리 (앞부분에 padding 처리)
return np.array([i[:max_len] if len(i) >= max_len else [0] * (max_len - len(i)) + i for i in seq])
def __len__(self): # dataset의 전체 길이 반환
return len(self.X)
def __getitem__(self, idx): # dataset 접근
X = self.X[idx]
label = self.label[idx]
return X, label
def cleaning_text(text):
cleaned_text = re.sub( r"[^a-zA-Z0-9.,@#!\s']+", "", text) # 특수문자 를 모두 지우는 작업을 수행합니다.
cleaned_text = cleaned_text.replace(u'\xa0',u' ') # No-break space를 unicode 빈칸으로 변환
cleaned_text = cleaned_text.replace('\u200a',' ') # unicode 빈칸을 빈칸으로 변환
return cleaned_text
data = list(map(cleaning_text, data))
tokenizer = get_tokenizer("basic_english")
vocab = torchtext.vocab.build_vocab_from_iterator(map(tokenizer, data))
vocab.insert_token('<pad>',0)
max_len = 20
# train set, validation set, test set으로 data set을 나눕니다. 8 : 1 : 1 의 비율로 나눕니다.
train, test = train_test_split(data, test_size = .2, random_state = 42)
val, test = train_test_split(test, test_size = .5, random_state = 42)
train_dataset = CustomDataset(train, vocab, tokenizer, max_len)
valid_dataset = CustomDataset(val, vocab, tokenizer, max_len)
test_dataset = CustomDataset(test, vocab, tokenizer, max_len)
batch_size = 32
train_dataloader = DataLoader(train_dataset, batch_size = batch_size, shuffle = True)
valid_dataloader = DataLoader(valid_dataset, batch_size = batch_size, shuffle = False)
test_dataloader = DataLoader(test_dataset, batch_size = batch_size, shuffle = False)
class NextWordPredictionModel(nn.Module):
def __init__(self, vocab_size, embedding_dims, hidden_dims, num_classes, dropout_ratio, set_super):
if set_super:
super().__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dims, padding_idx = 0) # padding index 설정 => gradient 계산에서 제외
self.hidden_dims = hidden_dims
self.layers = nn.ModuleList()
self.num_classes = num_classes
for i in range(len(self.hidden_dims) - 1):
self.layers.append(nn.Linear(self.hidden_dims[i], self.hidden_dims[i+1]))
self.layers.append(nn.BatchNorm1d(self.hidden_dims[i+1]))
self.layers.append(nn.ReLU())
self.layers.append(nn.Dropout(dropout_ratio))
self.classifier = nn.Linear(self.hidden_dims[-1], self.num_classes)
self.softmax = nn.LogSoftmax(dim = 1)
def forward(self, x):
'''
INPUT:
x: [batch_size, sequence_len] # padding 제외
OUTPUT:
output : [batch_size, vocab_size]
'''
x = self.embedding(x) # [batch_size, sequence_len, embedding_dim]
x = torch.sum(x, dim=1) # [batch_size, embedding_dim] 각 문장에 대해 임베딩된 단어들을 합쳐서, 해당 문장에 대한 임베딩 벡터로 만들어줍니다.
for layer in self.layers:
x = layer(x)
output = self.classifier(x) # [batch_size, num_classes]
output = self.softmax(output) # [batch_size, num_classes]
return output
def count_parameters(self):
return sum(p.numel() for p in self.parameters() if p.requires_grad)
# training 코드, evaluation 코드, training loop 코드
def training(model, dataloader, train_dataset, criterion, optimizer, device, epoch, num_epochs):
model.train() # 모델을 학습 모드로 설정
train_loss = 0.0
train_accuracy = 0
tbar = tqdm(dataloader)
for texts, labels in tbar:
texts = texts.to(device)
labels = labels.to(device)
# 순전파
outputs = model(texts)
loss = criterion(outputs, labels)
# 역전파 및 가중치 업데이트
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 손실과 정확도 계산
train_loss += loss.item()
# torch.max에서 dim 인자에 값을 추가할 경우, 해당 dimension에서 최댓값과 최댓값에 해당하는 인덱스를 반환
_, predicted = torch.max(outputs, dim=1)
train_accuracy += (predicted == labels).sum().item()
# tqdm의 진행바에 표시될 설명 텍스트를 설정
tbar.set_description(f"Epoch [{epoch+1}/{num_epochs}], Train Loss: {loss.item():.4f}")
# 에폭별 학습 결과 출력
train_loss = train_loss / len(dataloader)
train_accuracy = train_accuracy / len(train_dataset)
return model, train_loss, train_accuracy
def evaluation(model, dataloader, val_dataset, criterion, device, epoch, num_epochs):
model.eval() # 모델을 평가 모드로 설정
valid_loss = 0.0
valid_accuracy = 0
with torch.no_grad(): # model의 업데이트 막기
tbar = tqdm(dataloader)
for texts, labels in tbar:
texts = texts.to(device)
labels = labels.to(device)
# 순전파
outputs = model(texts)
loss = criterion(outputs, labels)
# 손실과 정확도 계산
valid_loss += loss.item()
# torch.max에서 dim 인자에 값을 추가할 경우, 해당 dimension에서 최댓값과 최댓값에 해당하는 인덱스를 반환
_, predicted = torch.max(outputs, 1)
# _, true_labels = torch.max(labels, dim=1)
valid_accuracy += (predicted == labels).sum().item()
# tqdm의 진행바에 표시될 설명 텍스트를 설정
tbar.set_description(f"Epoch [{epoch+1}/{num_epochs}], Valid Loss: {loss.item():.4f}")
valid_loss = valid_loss / len(dataloader)
valid_accuracy = valid_accuracy / len(val_dataset)
return model, valid_loss, valid_accuracy
def training_loop(model, train_dataloader, valid_dataloader, train_dataset, val_dataset, criterion, optimizer, device, num_epochs, patience, model_name):
best_valid_loss = float('inf') # 가장 좋은 validation loss를 저장
early_stop_counter = 0 # 카운터
valid_max_accuracy = -1
for epoch in range(num_epochs):
model, train_loss, train_accuracy = training(model, train_dataloader, train_dataset, criterion, optimizer, device, epoch, num_epochs)
model, valid_loss, valid_accuracy = evaluation(model, valid_dataloader, val_dataset, criterion, device, epoch, num_epochs)
if valid_accuracy > valid_max_accuracy:
valid_max_accuracy = valid_accuracy
# validation loss가 감소하면 모델 저장 및 카운터 리셋
if valid_loss < best_valid_loss:
best_valid_loss = valid_loss
torch.save(model.state_dict(), f"./model_{model_name}.pt")
early_stop_counter = 0
# validation loss가 증가하거나 같으면 카운터 증가
else:
early_stop_counter += 1
print(f"Epoch [{epoch + 1}/{num_epochs}], Train Loss: {train_loss:.4f}, Train Accuracy: {train_accuracy:.4f} Valid Loss: {valid_loss:.4f}, Valid Accuracy: {valid_accuracy:.4f}")
# 조기 종료 카운터가 설정한 patience를 초과하면 학습 종료
if early_stop_counter >= patience:
print("Early stopping")
break
return model, valid_max_accuracy
lr = 1e-3
vocab_size = len(vocab.get_stoi())
embedding_dims = 512
hidden_dims = [embedding_dims, embedding_dims*4, embedding_dims*2, embedding_dims]
model = NextWordPredictionModel(vocab_size = vocab_size, embedding_dims = embedding_dims, hidden_dims = hidden_dims, num_classes = vocab_size, \
dropout_ratio = 0.2, set_super = True).to(device)
num_epochs = 100
patience = 3
model_name = 'next'
optimizer = optim.Adam(model.parameters(), lr = lr)
criterion = nn.NLLLoss(ignore_index=0) # padding 한 부분 제외
model, valid_max_accuracy = training_loop(model, train_dataloader, valid_dataloader, train_dataset, valid_dataset, criterion, optimizer, device, num_epochs, patience, model_name)
print('Valid max accuracy : ', valid_max_accuracy)
# 평가
model.load_state_dict(torch.load("./model_next.pt")) # 모델 불러오기
model = model.to(device)
model.eval()
total_labels = []
total_preds = []
with torch.no_grad():
for texts, labels in tqdm(test_dataloader):
texts = texts.to(device)
labels = labels
outputs = model(texts)
# torch.max에서 dim 인자에 값을 추가할 경우, 해당 dimension에서 최댓값과 최댓값에 해당하는 인덱스를 반환
_, predicted = torch.max(outputs.data, 1)
total_preds.extend(predicted.detach().cpu().tolist())
total_labels.extend(labels.tolist())
total_preds = np.array(total_preds)
total_labels = np.array(total_labels)
nwp_dnn_acc = accuracy_score(total_labels, total_preds) # 정확도 계산
print("Next word prediction DNN model accuracy : ", nwp_dnn_acc)
3-5 CNN 구현
import numpy as np # 기본적인 연산을 위한 라이브러리
import matplotlib.pyplot as plt # 그림이나 그래프를 그리기 위한 라이브러리
from tqdm.notebook import tqdm # 상태 바를 나타내기 위한 라이브러리
import math # 수학 계산을 위한 라이브러
import torch # PyTorch 라이브러리
import torch.nn as nn # 모델 구성을 위한 라이브러리
import torch.optim as optim # optimizer 설정을 위한 라이브러리
from torch.utils.data import Dataset, DataLoader # 데이터셋 설정을 위한 라이브러리
import torch.nn.functional as F # torch에서 수학적인 function을 쉽게 불러오기 위한 라이브러리
import torchvision.transforms as T # 이미지의 다양성을 주기 위한 라이브러리
import torchvision # torch에서 이미지를 처리하기 위한 라이브러
import torchvision.utils as vutils # torch로 구성된 이미지를 쉽게 구성하기 위한 라이브러리
from sklearn.metrics import accuracy_score # 정확도 성능지표 측정
# seed 고정
import random
import torch.backends.cudnn as cudnn
def random_seed(seed_num):
torch.manual_seed(seed_num)
torch.cuda.manual_seed(seed_num)
torch.cuda.manual_seed_all(seed_num)
np.random.seed(seed_num)
cudnn.benchmark = False
cudnn.deterministic = True
random.seed(seed_num)
random_seed(42)
# Hyper parameter
patience = 3
verbose = True
device = 'cuda:0' # gpu 설정
# MNIST 분류를 위한 CNN 모델
class CNN(nn.Module):
def __init__(self, num_classes, dropout_ratio):
super(CNN, self).__init__()
self.num_classes = num_classes
self.layer = nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=16, kernel_size=5), # [BATCH_SIZE, 1, 28, 28] -> [BATCH_SIZE, 16, 24, 24]
nn.ReLU(), # ReLU 활성화 함수 적용
nn.Conv2d(in_channels=16, out_channels=32, kernel_size=5), # [BATCH_SIZE, 16, 24, 24] -> [BATCH_SIZE, 32, 20, 20]
nn.ReLU(), # ReLU 활성화 함수 적용
nn.MaxPool2d(kernel_size=2), # [BATCH_SIZE, 32, 20, 20] -> [BATCH_SIZE, 32, 10, 10]
nn.Dropout(dropout_ratio),
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=5), # [BATCH_SIZE, 32, 10, 10] -> [BATCH_SIZE, 64, 6, 6]
nn.ReLU(),
nn.MaxPool2d(kernel_size=2), # 크기를 1/2로 줄입니다. [BATCH_SIZE, 64, 6, 6] -> [BATCH_SIZE, 64, 3, 3]
nn.Dropout(dropout_ratio),
)
self.fc_layer = nn.Linear(64*3*3, self.num_classes) # [BATCH_SIZE, 64*3*3] -> [BATCH_SIZE, num_classes]
self.softmax = nn.LogSoftmax(dim = 1)
def forward(self,x):
'''
Input and Output Summary
Input :
x : [batch_size, channel, height, width]
Output :
pred : [batch_size, num_classes]
'''
out = self.layer(x) # self.layer에 정의한 Sequential의 연산을 차례대로 다 실행합니다. [BATCH_SIZE, 64, 3, 3]
out = out.view(x.size(0), -1) # [BATCH_SIZE, 64*3*3]
pred = self.fc_layer(out) # [BATCH_SIZE, num_classes]
pred = self.softmax(pred) # [BATCH_SIZE, num_classes]
return pred
def weight_initialization(self):
for m in self.modules():
if isinstance(m, nn.Conv2d) or isinstance(m, nn.Linear):
nn.init.kaiming_normal_(m.weight)
nn.init.zeros_(m.bias)
def count_parameters(self):
return sum(p.numel() for p in self.parameters() if p.requires_grad)
num_classes = 10
dropout_ratio = 0.5
model = CNN(num_classes = num_classes, dropout_ratio = dropout_ratio).to(device)
model.count_parameters() # 참고로 DNN 구현(2)에 있는 모델은 약 57만개의 파라미터, 반면에 CNN은 layer 가 DNN 보다 하나 더 많음에도 불구하고, 훨씬 적음
# 데이터를 불러올 때, 필요한 변환(transform)을 정의합니다.
mnist_transform = T.Compose([
T.ToTensor(), # 텐서 형식으로 변환
])
# torchvision 라이브러리를 사용하여 MNIST 데이터 셋을 불러옵니다.
download_root = './MNIST_DATASET'
train_dataset = torchvision.datasets.MNIST(download_root, transform=mnist_transform, train=True, download=True) # train dataset 다운로드
test_dataset = torchvision.datasets.MNIST(download_root, transform=mnist_transform, train=False, download=True) # test dataset 다운로드
# 데이터 셋을 학습 데이터 셋과 검증 데이터 셋으로 분리합니다.
total_size = len(train_dataset)
train_num, valid_num = int(total_size * 0.8), int(total_size * 0.2) # 8 : 2 = train : valid
print("Train dataset 개수 : ", train_num)
print("Validation dataset 개수 : ", valid_num)
train_dataset,valid_dataset = torch.utils.data.random_split(train_dataset, [train_num, valid_num]) # train - valid set 나누기
# 앞서 선언한 Dataset을 인자로 주어 DataLoader를 선언합니다.
batch_size = 32
train_dataloader = DataLoader(train_dataset, batch_size = batch_size, shuffle = True)
valid_dataloader = DataLoader(valid_dataset, batch_size = batch_size, shuffle = False)
test_dataloader = DataLoader(test_dataset, batch_size = batch_size, shuffle = False)
# training 코드, evaluation 코드, training_loop 코드
def training(model, dataloader, train_dataset, criterion, optimizer, device, epoch, num_epochs):
model.train() # 모델을 학습 모드로 설정
train_loss = 0.0
train_accuracy = 0
tbar = tqdm(dataloader)
for images, labels in tbar:
images = images.to(device)
labels = labels.to(device)
# 순전파
outputs = model(images)
loss = criterion(outputs, labels)
# 역전파 및 가중치 업데이트
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 손실과 정확도 계산
train_loss += loss.item()
# torch.max에서 dim 인자에 값을 추가할 경우, 해당 dimension에서 최댓값과 최댓값에 해당하는 인덱스를 반환
_, predicted = torch.max(outputs, 1)
train_accuracy += (predicted == labels).sum().item()
# tqdm의 진행바에 표시될 설명 텍스트를 설정
tbar.set_description(f"Epoch [{epoch+1}/{num_epochs}], Train Loss: {loss.item():.4f}")
# 에폭별 학습 결과 출력
train_loss = train_loss / len(dataloader)
train_accuracy = train_accuracy / len(train_dataset)
return model, train_loss, train_accuracy
def evaluation(model, dataloader, val_dataset, criterion, device, epoch, num_epochs):
model.eval() # 모델을 평가 모드로 설정
valid_loss = 0.0
valid_accuracy = 0
with torch.no_grad(): # model의 업데이트 막기
tbar = tqdm(dataloader)
for images, labels in tbar:
images = images.to(device)
labels = labels.to(device)
# 순전파
outputs = model(images)
loss = criterion(outputs, labels)
# 손실과 정확도 계산
valid_loss += loss.item()
# torch.max에서 dim 인자에 값을 추가할 경우, 해당 dimension에서 최댓값과 최댓값에 해당하는 인덱스를 반환
_, predicted = torch.max(outputs, 1)
valid_accuracy += (predicted == labels).sum().item()
# tqdm의 진행바에 표시될 설명 텍스트를 설정
tbar.set_description(f"Epoch [{epoch+1}/{num_epochs}], Valid Loss: {loss.item():.4f}")
valid_loss = valid_loss / len(dataloader)
valid_accuracy = valid_accuracy / len(val_dataset)
return model, valid_loss, valid_accuracy
def training_loop(model, train_dataloader, valid_dataloader, train_dataset, val_dataset, criterion, optimizer, device, num_epochs, patience, model_name):
best_valid_loss = float('inf') # 가장 좋은 validation loss를 저장
early_stop_counter = 0 # 카운터
valid_max_accuracy = -1
for epoch in range(num_epochs):
model, train_loss, train_accuracy = training(model, train_dataloader, train_dataset, criterion, optimizer, device, epoch, num_epochs)
model, valid_loss, valid_accuracy = evaluation(model, valid_dataloader, val_dataset, criterion, device, epoch, num_epochs)
if valid_accuracy > valid_max_accuracy:
valid_max_accuracy = valid_accuracy
# validation loss가 감소하면 모델 저장 및 카운터 리셋
if valid_loss < best_valid_loss:
best_valid_loss = valid_loss
torch.save(model.state_dict(), f"./model_{model_name}.pt")
early_stop_counter = 0
# validation loss가 증가하거나 같으면 카운터 증가
else:
early_stop_counter += 1
print(f"Epoch [{epoch + 1}/{num_epochs}], Train Loss: {train_loss:.4f}, Train Accuracy: {train_accuracy:.4f} Valid Loss: {valid_loss:.4f}, Valid Accuracy: {valid_accuracy:.4f}")
# 조기 종료 카운터가 설정한 patience를 초과하면 학습 종료
if early_stop_counter >= patience:
print("Early stopping")
break
return model, valid_max_accuracy
num_epochs = 100
patience = 3
model_name = 'exp1'
lr = 1e-3
criterion = nn.NLLLoss() # NLL loss 후 softmax 를 취하면 CrossEntropy Loss 를 취한 것과 동일하게 됨
optimizer = optim.Adam(model.parameters(), lr = lr)
model, valid_max_accuracy = training_loop(model, train_dataloader, valid_dataloader, train_dataset, valid_dataset, criterion, optimizer, device, num_epochs, patience, model_name)
print('Valid max accuracy : ', valid_max_accuracy)
model.load_state_dict(torch.load("./model_exp1.pt")) # 모델 불러오기
model = model.to(device)
model.eval()
total_labels = []
total_preds = []
with torch.no_grad():
for images, labels in tqdm(test_dataloader):
images = images.to(device)
labels = labels
outputs = model(images)
# torch.max에서 dim 인자에 값을 추가할 경우, 해당 dimension에서 최댓값과 최댓값에 해당하는 인덱스를 반환
_, predicted = torch.max(outputs.data, 1)
total_preds.extend(predicted.detach().cpu().tolist())
total_labels.extend(labels.tolist())
total_preds = np.array(total_preds)
total_labels = np.array(total_labels)
custom_cnn_acc = accuracy_score(total_labels, total_preds) # 정확도 계산
print("Custom CNN model accuracy : ", custom_cnn_acc)
3-6 RNN 구현
import numpy as np # 기본적인 연산을 위한 라이브러리
import matplotlib.pyplot as plt # 그림이나 그래프를 그리기 위한 라이브러리
from tqdm.notebook import tqdm # 상태 바를 나타내기 위한 라이브러리
import pandas as pd # 데이터프레임을 조작하기 위한 라이브러리
import torch # PyTorch 라이브러리
import torch.nn as nn # 모델 구성을 위한 라이브러리
import torch.optim as optim # optimizer 설정을 위한 라이브러리
from torch.utils.data import Dataset, DataLoader # 데이터셋 설정을 위한 라이브러리
import torch.nn.functional as F # torch에서 수학적인 function을 쉽게 불러오기 위한 라이브러리
from torchtext.data import get_tokenizer # torch에서 tokenizer를 얻기 위한 라이브러리
import torchtext # torch에서 text를 더 잘 처리하기 위한 라이브러리
from sklearn.metrics import accuracy_score # 성능지표 측정
from sklearn.model_selection import train_test_split # train-validation-test set 나누는 라이브러리
import re # text 전처리를 위한 라이브러리
# seed 고정
import random
import torch.backends.cudnn as cudnn
def random_seed(seed_num):
torch.manual_seed(seed_num)
torch.cuda.manual_seed(seed_num)
torch.cuda.manual_seed_all(seed_num)
np.random.seed(seed_num)
cudnn.benchmark = False
cudnn.deterministic = True
random.seed(seed_num)
random_seed(42)
device = 'cuda:0'
# DNN 에서 갖고 오기
data_csv = pd.read_csv('data/medium_data.csv')
data = data_csv['title']
class CustomDataset(Dataset):
def __init__(self, data, vocab, tokenizer, max_len):
self.data = data
self.vocab = vocab
self.max_len = max_len
self.tokenizer = tokenizer
seq = self.make_sequence(self.data, self.vocab, self.tokenizer) # next word prediction을 하기 위한 형태로 변환
self.seq = self.pre_zeropadding(seq, self.max_len) # zero padding으로 채워줌
self.X = torch.tensor(self.seq[:,:-1])
self.label = torch.tensor(self.seq[:,-1])
def make_sequence(self, data, vocab, tokenizer):
seq = []
for i in data:
token_id = vocab.lookup_indices(tokenizer(i))
for j in range(1, len(token_id)):
sequence = token_id[:j+1]
seq.append(sequence)
return seq
def pre_zeropadding(self, seq, max_len): # max_len 길이에 맞춰서 0 으로 padding 처리 (앞부분에 padding 처리)
return np.array([i[:max_len] if len(i) >= max_len else [0] * (max_len - len(i)) + i for i in seq])
def __len__(self): # dataset의 전체 길이 반환
return len(self.X)
def __getitem__(self, idx): # dataset 접근
X = self.X[idx]
label = self.label[idx]
return X, label
def cleaning_text(text):
cleaned_text = re.sub( r"[^a-zA-Z0-9.,@#!\s']+", "", text) # 특수문자 를 모두 지우는 작업을 수행합니다.
cleaned_text = cleaned_text.replace(u'\xa0',u' ') # No-break space를 unicode 빈칸으로 변환
cleaned_text = cleaned_text.replace('\u200a',' ') # unicode 빈칸을 빈칸으로 변환
return cleaned_text
data = list(map(cleaning_text, data))
tokenizer = get_tokenizer("basic_english")
vocab = torchtext.vocab.build_vocab_from_iterator(map(tokenizer, data))
vocab.insert_token('<pad>',0)
max_len = 20
# train set과 validation set, test set을 각각 나눕니다. 8 : 1 : 1 의 비율로 나눕니다.
train, test = train_test_split(data, test_size = .2, random_state = 42)
val, test = train_test_split(test, test_size = .5, random_state = 42)
print("Train 개수: ", len(train))
print("Validation 개수: ", len(val))
print("Test 개수: ", len(test))
train_dataset = CustomDataset(train, vocab, tokenizer, max_len)
valid_dataset = CustomDataset(val, vocab, tokenizer, max_len)
test_dataset = CustomDataset(test, vocab, tokenizer, max_len)
batch_size = 32
train_dataloader = DataLoader(train_dataset, batch_size = batch_size, shuffle = True)
valid_dataloader = DataLoader(valid_dataset, batch_size = batch_size, shuffle = False)
test_dataloader = DataLoader(test_dataset, batch_size = batch_size, shuffle = False)
class RNN(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_size):
super(RNN, self).__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim, padding_idx=0)
self.rnn = nn.RNN(embedding_dim, hidden_size, batch_first=True) # batch_first=True는 입력의 첫 번째 차원이 batch 크기임을 나타냅니다.
self.fc = nn.Linear(hidden_size, vocab_size)
def forward(self, x):
'''
INPUT:
x: [batch_size, seq_len]
OUTPUT:
output: [batch_size, vocab_size]
'''
x = self.embedding(x) # [batch_size, sequence_len, embedding_dim]
# 첫 번째 리턴값인 output은 모든 time step의 hidden state를 포함한 출력입니다.
# 두 번째 리턴값인 h_0 는 마지막 time step의 hidden state를 의미합니다.
output, h_0 = self.rnn(x) # output: [batch_size, seq_len, hidden_dim] / h_0: [1, batch_size, hidden_dim]
return self.fc(output[:,-1,:]) # [batch_size, vocab_size]
# training 코드, evaluation 코드, training_loop 코드
def training(model, dataloader, train_dataset, criterion, optimizer, device, epoch, num_epochs):
model.train() # 모델을 학습 모드로 설정
train_loss = 0.0
train_accuracy = 0
tbar = tqdm(dataloader)
for texts, labels in tbar:
texts = texts.to(device)
labels = labels.to(device)
# 순전파
outputs = model(texts)
loss = criterion(outputs, labels)
# 역전파 및 가중치 업데이트
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 손실과 정확도 계산
train_loss += loss.item()
# torch.max에서 dim 인자에 값을 추가할 경우, 해당 dimension에서 최댓값과 최댓값에 해당하는 인덱스를 반환
_, predicted = torch.max(outputs, dim=1)
train_accuracy += (predicted == labels).sum().item()
# tqdm의 진행바에 표시될 설명 텍스트를 설정
tbar.set_description(f"Epoch [{epoch+1}/{num_epochs}], Train Loss: {loss.item():.4f}")
# 에폭별 학습 결과 출력
train_loss = train_loss / len(dataloader)
train_accuracy = train_accuracy / len(train_dataset)
return model, train_loss, train_accuracy
def evaluation(model, dataloader, valid_dataset, criterion, device, epoch, num_epochs):
model.eval() # 모델을 평가 모드로 설정
valid_loss = 0.0
valid_accuracy = 0
with torch.no_grad(): # model의 업데이트 막기
tbar = tqdm(dataloader)
for texts, labels in tbar:
texts = texts.to(device)
labels = labels.to(device)
# 순전파
outputs = model(texts)
loss = criterion(outputs, labels)
# 손실과 정확도 계산
valid_loss += loss.item()
# torch.max에서 dim 인자에 값을 추가할 경우, 해당 dimension에서 최댓값과 최댓값에 해당하는 인덱스를 반환
_, predicted = torch.max(outputs, 1)
# _, true_labels = torch.max(labels, dim=1)
valid_accuracy += (predicted == labels).sum().item()
# tqdm의 진행바에 표시될 설명 텍스트를 설정
tbar.set_description(f"Epoch [{epoch+1}/{num_epochs}], Valid Loss: {loss.item():.4f}")
valid_loss = valid_loss / len(dataloader)
valid_accuracy = valid_accuracy / len(valid_dataset)
return model, valid_loss, valid_accuracy
def training_loop(model, train_dataloader, valid_dataloader, train_dataset, val_dataset, criterion, optimizer, device, num_epochs, patience, model_name):
best_valid_loss = float('inf') # 가장 좋은 validation loss를 저장
early_stop_counter = 0 # 카운터
valid_max_accuracy = -1
for epoch in range(num_epochs):
model, train_loss, train_accuracy = training(model, train_dataloader, train_dataset, criterion, optimizer, device, epoch, num_epochs)
model, valid_loss, valid_accuracy = evaluation(model, valid_dataloader, val_dataset, criterion, device, epoch, num_epochs)
if valid_accuracy > valid_max_accuracy:
valid_max_accuracy = valid_accuracy
# validation loss가 감소하면 모델 저장 및 카운터 리셋
if valid_loss < best_valid_loss:
best_valid_loss = valid_loss
torch.save(model.state_dict(), f"./model_{model_name}.pt")
early_stop_counter = 0
# validation loss가 증가하거나 같으면 카운터 증가
else:
early_stop_counter += 1
print(f"Epoch [{epoch + 1}/{num_epochs}], Train Loss: {train_loss:.4f}, Train Accuracy: {train_accuracy:.4f} Valid Loss: {valid_loss:.4f}, Valid Accuracy: {valid_accuracy:.4f}")
# 조기 종료 카운터가 설정한 patience를 초과하면 학습 종료
if early_stop_counter >= patience:
print("Early stopping")
break
return model, valid_max_accuracy
num_epochs = 100
patience = 3
model_name = 'RNN'
vocab_size = len(vocab)
embedding_dim = 512
hidden_size = 256
model = RNN(vocab_size, embedding_dim, hidden_size).to(device)
lr = 1e-3
criterion = nn.CrossEntropyLoss(ignore_index = 0)
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
model, valid_max_accuracy = training_loop(model, train_dataloader, valid_dataloader, train_dataset, valid_dataset, criterion, optimizer, device, num_epochs, patience, model_name)
print('Valid max accuracy : ', valid_max_accuracy)
# 평가
model.load_state_dict(torch.load("./model_RNN.pt")) # 모델 불러오기
model = model.to(device)
model.eval()
total_labels = []
total_preds = []
with torch.no_grad():
for texts, labels in tqdm(test_dataloader):
texts = texts.to(device)
labels = labels
outputs = model(texts)
# torch.max에서 dim 인자에 값을 추가할 경우, 해당 dimension에서 최댓값과 최댓값에 해당하는 인덱스를 반환
_, predicted = torch.max(outputs.data, 1)
total_preds.extend(predicted.detach().cpu().tolist())
total_labels.extend(labels.tolist())
total_preds = np.array(total_preds)
total_labels = np.array(total_labels)
nwp_rnn_acc = accuracy_score(total_labels, total_preds) # 정확도 계산
print("Next word prediction RNN model accuracy : ", nwp_rnn_acc)
4. Transfer Learning
4-1 전이학습이란?
Pretrained Model이란
● Pretrained model은 대규모 데이터셋을 기반으로 학습된 모델로, 학습한 task에 대한 일반적인 지식을 갖고 있음
● 최근 GPT, PALM, Stable-Diffusion 등 대규모 데이터로 학습된 pretrained model이 등장하면서 중요성이 대두되고 있음
전이 학습이란?
● 사전 학습된 모델 (pretrained model)의 지식을 다른 task에 활용하는 것
● 모델이 이미 학습한 일반적인 지식을 기반으로 더 빠르고 효과적이게 새로운 지식을 학습할 수 있음
4-2 timm과 Hugging Face을 통한 전이 학습
import torch # pytorch 불러오기
import numpy as np # numpy 불러오기
import warnings # 경고 문구 제거
import matplotlib.pyplot as plt # 그래프를 그리기 위한 라이브러리
import pandas as pd # 데이터 프레임을 읽기 위한 라이브러리
from sklearn.model_selection import train_test_split # train test 를 나누기 위한 라이브러리
from sklearn.metrics import accuracy_score # 정확도 계산 라이브러리
from tqdm.notebook import tqdm # 진행상황 바 표현
warnings.filterwarnings('ignore')
import torch.nn as nn # 모델 구성을 위한 라이브러리
from torchvision.datasets import CIFAR10 # CIFAR10 데이터셋 불러오는 라이브러리
import torchvision.transforms as T # 이미지 변환을 위한 라이브러리
import torch.optim as optim # optimizer 설정을 위한 라이브러리
# seed 고정
import random
import torch.backends.cudnn as cudnn
def random_seed(seed_num):
torch.manual_seed(seed_num)
torch.cuda.manual_seed(seed_num)
torch.cuda.manual_seed_all(seed_num)
np.random.seed(seed_num)
cudnn.benchmark = False
cudnn.deterministic = True
random.seed(seed_num)
random_seed(42)
# data 불러오기
data = pd.read_csv('IMDB Dataset.csv')
print(data.shape)
data.head()
dic = {'positive':0, 'negative':1} # positive 면 0으로, negative면 1로 변환
data['sentiment'] = data['sentiment'].map(dic)
# data 8:1:1 로 나누기
train, test = train_test_split(data, test_size = .2, random_state = 42)
val, test = train_test_split(test, test_size = .5, random_state = 42)
print("Train 개수: ", len(train))
print("Validation 개수: ", len(val))
print("Test 개수: ", len(test))
train.reset_index(drop=True, inplace=True) # index 재정렬
val.reset_index(drop=True, inplace=True) # index 재정렬
test.reset_index(drop=True, inplace=True) # index 재정렬
train['review'] = train['review'].apply(lambda x: f'[CLS] {x} [SEP]') # 문장의 앞뒤에 [CLS]와 [SEP] 삽입
val['review'] = val['review'].apply(lambda x: f'[CLS] {x} [SEP]') # 문장의 앞뒤에 [CLS]와 [SEP] 삽입
test['review'] = test['review'].apply(lambda x: f'[CLS] {x} [SEP]') # 문장의 앞뒤에 [CLS]와 [SEP] 삽입
# 각 문장들만 추출
train_sentences = train['review'].values
val_sentences = val['review'].values
test_sentences = test['review'].values
# 정답값 추출
train_label = train['sentiment'].values
val_label = val['sentiment'].values
test_label = test['sentiment'].values
# BERT의 tokenizer로 문장을 토큰으로 분리
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-cased') # 기존에 학습된 BERT tokenizer 불러오기
train_tokenized_texts = list(map(lambda x: tokenizer.tokenize(x), train_sentences))
val_tokenized_texts = list(map(lambda x: tokenizer.tokenize(x), val_sentences))
test_tokenized_texts = list(map(lambda x: tokenizer.tokenize(x), test_sentences))
# 입력 토큰의 최대 시퀀스 길이
MAX_LEN = 128
# 토큰을 숫자 인덱스로 변환
train_input_ids = list(map(lambda x: tokenizer.convert_tokens_to_ids(x), train_tokenized_texts)) # convert_tokens_to_ids로 정수 형태로 변환해주기
val_input_ids = list(map(lambda x: tokenizer.convert_tokens_to_ids(x), val_tokenized_texts))
test_input_ids = list(map(lambda x: tokenizer.convert_tokens_to_ids(x), test_tokenized_texts))
# 문장을 MAX_LEN 길이에 맞게 자르고, 모자란 부분을 패딩 0으로 채움
def zero_padding(id_list,max_len):
return np.array([i[:max_len] if len(i) >= max_len else i + [0] * (max_len - len(i)) for i in id_list])
train_input_ids = zero_padding(train_input_ids, MAX_LEN)
val_input_ids = zero_padding(val_input_ids, MAX_LEN)
test_input_ids = zero_padding(test_input_ids, MAX_LEN)
# 마스크 만들기
train_masks = train_input_ids > 0 # 패딩이 아닌 부분은 0보다 큰 값이 있으므로 flag를 통해서 마스크를 구성할 수 있습니다.
val_masks = val_input_ids > 0
test_masks = test_input_ids > 0
# 모두 tensor로 변환
train_inputs = torch.tensor(train_input_ids) # train set의 input token id들
train_labels = torch.tensor(train_label) # train set의 label들
train_masks = torch.tensor(train_masks) # train set의 mask
validation_inputs = torch.tensor(val_input_ids) # valid set의 input token id들
validation_labels = torch.tensor(val_label) # valid set의 label들
validation_masks = torch.tensor(val_masks) # valid set의 mask
test_inputs = torch.tensor(test_input_ids) # test set의 input token id들
test_labels = torch.tensor(test_label) # test set의 label들
test_masks = torch.tensor(test_masks) # test set의 mask
class EmotionData(torch.utils.data.Dataset): # custom 데이터셋 구성
def __init__(self, inputs, masks, labels):
self.inputs = inputs
self.masks = masks
self.labels = labels
def __len__(self):
return len(self.inputs)
def __getitem__(self,idx):
inputs_value = self.inputs[idx]
masks_value = self.masks[idx]
labels_value = self.labels[idx]
return inputs_value, masks_value, labels_value
train_dataset = EmotionData(train_inputs, train_masks, train_labels)
valid_dataset = EmotionData(validation_inputs, validation_masks, validation_labels)
test_dataset = EmotionData(test_inputs, test_masks, test_labels)
BATCH_SIZE = 32
train_dataloader = torch.utils.data.DataLoader(train_dataset, batch_size = BATCH_SIZE, shuffle = True, drop_last = False, num_workers = 8)
valid_dataloader = torch.utils.data.DataLoader(valid_dataset, batch_size = BATCH_SIZE, shuffle = False, drop_last = False, num_workers = 8)
test_dataloader = torch.utils.data.DataLoader(test_dataset, batch_size = BATCH_SIZE, shuffle = False, drop_last = False, num_workers = 8)
model = BertForSequenceClassification.from_pretrained("bert-base-cased").to(device) # pretrained bert 모델 불러오기
# training 코드, evaluation 코드, training_loop 코드
def training(model, dataloader, train_dataset, optimizer, device, epoch, num_epochs):
model.train() # 모델을 학습 모드로 설정
train_loss = 0.0
train_accuracy = 0
tbar = tqdm(dataloader)
for batch in tbar:
input_ = batch[0].to(device)
mask = batch[1].to(device)
labels = batch[2].to(device)
# 순전파
output = model(input_,
attention_mask= mask,
labels=labels)
loss = output['loss'] # 얘 확인
# 역전파 및 가중치 업데이트
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 손실과 정확도 계산
train_loss += loss.item()
# torch.max에서 dim 인자에 값을 추가할 경우, 해당 dimension에서 최댓값과 최댓값에 해당하는 인덱스를 반환
_, predicted = torch.max(output['logits'], 1)
train_accuracy += (predicted == labels).sum().item()
# tqdm의 진행바에 표시될 설명 텍스트를 설정
tbar.set_description(f"Epoch [{epoch+1}/{num_epochs}], Train Loss: {loss.item():.4f}")
# 에폭별 학습 결과 출력
train_loss = train_loss / len(dataloader)
train_accuracy = train_accuracy / len(train_dataset)
return model, train_loss, train_accuracy
def evaluation(model, dataloader, val_dataset, device, epoch, num_epochs):
model.eval() # 모델을 평가 모드로 설정
valid_accuracy = 0
with torch.no_grad(): # model의 업데이트 막기
tbar = tqdm(dataloader)
for batch in tbar:
input_ = batch[0].to(device)
mask = batch[1].to(device)
labels = batch[2].to(device)
# 순전파
output = model(input_,
attention_mask= mask,
labels=labels)
# torch.max에서 dim 인자에 값을 추가할 경우, 해당 dimension에서 최댓값과 최댓값에 해당하는 인덱스를 반환
_, predicted = torch.max(output['logits'], 1)
valid_accuracy += (predicted == labels).sum().item()
# tqdm의 진행바에 표시될 설명 텍스트를 설정
tbar.set_description(f"Epoch [{epoch+1}/{num_epochs}]")
valid_accuracy = valid_accuracy / len(val_dataset)
return model, valid_accuracy
def training_loop(model, train_dataloader, valid_dataloader, train_dataset, val_dataset, optimizer, device, num_epochs, model_name):
best_valid_loss = float('inf') # 가장 좋은 validation loss를 저장
valid_max_accuracy = -1
for epoch in range(num_epochs):
model, train_loss, train_accuracy = training(model, train_dataloader, train_dataset, optimizer, device, epoch, num_epochs)
model, valid_accuracy = evaluation(model, valid_dataloader, val_dataset, device, epoch, num_epochs)
if valid_accuracy > valid_max_accuracy:
valid_max_accuracy = valid_accuracy
torch.save(model.state_dict(), f"./model_{model_name}.pt")
print(f"Epoch [{epoch + 1}/{num_epochs}], Train Loss: {train_loss:.4f}, Train Accuracy: {train_accuracy:.4f}, Valid Accuracy: {valid_accuracy:.4f}")
return model, valid_max_accuracy
# 모델 전체 fine tuning
num_epochs = 2
model_name = 'bert1'
lr = 1e-5
optimizer = optim.Adam(model.parameters(), lr=lr)
model, valid_max_accuracy = training_loop(model, train_dataloader, valid_dataloader, train_dataset, valid_dataset, optimizer, device, num_epochs, model_name)
print('Valid max accuracy : ', valid_max_accuracy)
model.load_state_dict(torch.load("./model_bert1.pt")) # 모델 불러오기
model = model.to(device)
model.eval()
total_labels = []
total_preds = []
total_probs = []
with torch.no_grad():
for batch in tqdm(test_dataloader):
input_ = batch[0].to(device)
mask = batch[1].to(device)
labels = batch[2].to(device)
output = model(input_,
attention_mask= mask,
labels=labels)
# torch.max에서 dim 인자에 값을 추가할 경우, 해당 dimension에서 최댓값과 최댓값에 해당하는 인덱스를 반환
_, predicted = torch.max(output['logits'], 1)
total_preds.extend(predicted.detach().cpu().tolist())
total_labels.extend(labels.tolist())
total_probs.append(output['logits'].detach().cpu().numpy())
total_preds = np.array(total_preds)
total_labels = np.array(total_labels)
total_probs = np.concatenate(total_probs, axis= 0)
acc = accuracy_score(total_labels, total_preds)
print("Full fine tuning model accuracy : ",acc)
5. Trouble Shooting
5-1 모니터링을 위한 TensorBoard와 Wandb
5-2 디버깅
6. PyTorch Lightning with Hydra
6-1 파이토치 라이트닝 소개
PyTorch Lightning
PyTorch에 대한 high-level 인터페이스를 제공하는 오픈소스 라이브러리
딥러닝 모델 구축의 코드 템플릿으로써 기능을 하여 코드를 작성할 때 좀 더 정돈되고 간결화된 코드를 작성
- 코드의 추상화 및 하드웨어 호출 자동화
- 다양한 콜백 함수와 로깅
- 16-bit precision
6-2 파이토치 코드를 파이토치 라이트닝 코드로 변환하기
__init__
forward
configure_optimizers
training_step
validation_step
test_step
predict_step
6-3 하이드라 소개
- 유지관리
- 코드의 일관성 유지
Hydra 특징
● Hydra는 OmegaConf에서 발전된 프레임워크로, OmegaConf에서의 yaml 데이터 포맷을 사용하며 변수 접근, 변수 참조
(${variable}) 등의 기능을 사용가능.
● 설정 파일의 값을 터미널의 커맨드라인을 통해 쉽게 추가하거나 변경가능.
● 나눠진 여러 설정 파일들을 이용하여 하나의 설정 파일처럼 유기적으로 구성하기 편리.
● 서로 다른 설정 파일의 실험 조합을 하나의 터미널의 커맨드라인으로 실행.
6-4 파이토치 라이트닝과 하이드라
Dataset, DataLoader:데이터와 관련된 파라미터(`data_dir`, `batch_size`, `valid_split`)를 설정 파일에 작성
LightningModule: CNN 구성과 관련된 파라미터(`model_name`, `num_classes`, `dropout_ratio`)를 설정 파일에 작성
optimizer, scheduler:LightningModule의 `configure_optimizers` 메서드에 필요한 optimizer, scheduler 파라미터를 설정 파일로 작성
Callbacks, logger, trainer:Trainer의 `callbacks`, `logger` 인자에 필요한 `EarlyStopping`, `LearningRateMonitor`, `WandbLogger`에 필요한
파라미터를 설정 파일로 작성
딥러닝 부터는 어렵구나.
정신차리자!